Данная статья продолжает цикл моих переводов статей Jakob Jenkov об оптимизации Java приложений.
Иногда вы хотите сохранить данные (обычно необработанные байты) в одном последовательном массиве для быстрого и легкого доступа, но вам нужно, чтобы размер массива можно было изменять или, по крайней мере, расширять. Массивы Java не поддаются изменению размера, поэтому одного использования массива недостаточно. Таким образом, чтобы получить массив с возможностью изменения размера для примитивных типов, вам нужно реализовать его самостоятельно. В этом уроке я покажу вам, как реализовать массив с изменяемым размером в Java.
Почему не ArrayList?
Вы можете задаться вопросом, почему бы просто не использовать ArrayList для этой цели. Ответ таков - вы можете, если одно из этих условий верно:
- В массиве вы сохраняете объект
- Вы сохраняете примитив и вам не важны скорость и память
Класс ArrayList работает только для объектов, а не для примитивных типов (byte, int, long и т.д.). Если вы используете ArrayList для хранения примитивных данных, они будут автоматически упакованы в объект при вставке в ArrayList и распакованы из этого объекта обратно в примитивный тип. Эта упаковка и распаковка добавляет накладные расходы на вставку и доступ к каждому элементу, чего вы не хотите, когда пытаетесь оптимизировать производительность (эта статья является частью моего цикла о производительности Java).
Кроме того, у вас нет гарантии того, где в памяти хранятся автоматически загруженные объекты. Они могут быть разбросаны по всей куче. Таким образом, последовательный доступ к ним может быть намного, намного медленнее, чем при последовательном хранении в памяти - в массиве примитивного типа.
Также, хранение примитива в его объектном аналоге (например, long в Long) приводит к значительным дополнительным затратам памяти на каждый элемент.
Изменяемый массив - репозиторий на GitHub
Код изменяемого массива, реализованный в этом руководстве, можно найти на GitHub:
https://github.com/jjenkov/java-resizable-array
Код состоит из 3 классов Java и 2 модульных тестов.
Применение изменяемых массивов
Представьте, что у вас есть сервер, принимающий сообщения разного размера. Некоторые сообщения очень маленькие (например, менее 4 КБ), другие размером до 1 МБ или даже больше. Если сервер не может видеть с самого начала сообщения, насколько большим в конечном итоге будет сообщение, нет способа предварительно выделить правильный объем памяти для этого сообщения. Альтернативой является "чрезмерное выделение", то есть выделение блока памяти, который, по нашему мнению, достаточно велик для хранения сообщения.
Если сервер получает сообщения от многих (более 100 тыс.) подключений одновременно, нам нужно ограничить объем памяти, который мы выделяем для каждого сообщения. Мы не можем просто выделить максимальный размер сообщения (например, 1 МБ или 16 МБ и т.д.) Для каждого буфера сообщений. Это приведет к быстрому истощению памяти сервера при увеличении количества подключений и сообщений! 100.000 x 1 МБ = 100 ГБ (приблизительно - не точно - но вы получаете картину).
Альтернатива состоит в том, чтобы начать с меньшего буфера, и если этот буфер оказывается недостаточно большим, чтобы вместить полное сообщение, мы расширяем буфер.
Расширение массива обходится дорого
Чтобы расширить массив, надо:
- Выделить новый, больший массив
- Скопировать в него данные старого массива
- удалить старый массив
Это дорогостоящий набор операций! Особенно копирование старых данных в новые данные становится все дороже и дороже, чем больше старый массив.
Обратите внимание, что в языках со встроенной сборкой мусора (например, Java, C # и т.д.) Вам явно не нужно освобождать старый массив, но виртуальная машина все равно должна это сделать, поэтому ваше приложение все равно рано или поздно заплатит цену освобождения.
Минимизация расширения
Чтобы свести к минимуму цену, заплаченную за расширение массива, вы хотите расширять его как можно реже, чтобы сделать его достаточно большим, чтобы вместить все сообщение.
Если мы предположим, что большинство сообщений небольшие, мы можем начать с небольшого буфера. Если размер сообщения превышает небольшой размер буфера, мы выделяем новый массив среднего размера и копируем данные в новый массив. Если сообщение также перерастает массив среднего размера, выделяется большой массив, и сообщение копируется в него. Большой массив должен быть максимально допустимого размера для сообщения. Если сообщение превышает размер большого буфера сообщений, оно слишком велико для обработки и должно быть отклонено сервером.
Используя эту стратегию, большинство сообщений будут использовать только небольшой буфер. Это означает, что память сервера используется более эффективно. 100.000 x 4 КБ (небольшой размер буфера) составляет всего 400 МБ. Большинство серверов должны быть в состоянии справиться с этим. Даже при 4 ГБ (1.000.000 x 4 КБ) современные серверы должны быть в состоянии справиться с этим.
Дизайн расширяемого массива
Массив с изменяемым размером обычно состоит из двух компонентов:
- Сам массив
- Расширяемый буфер
Буфер содержит один большой массив. Этот массив разделен на три секции. Один раздел для небольших массивов, один для массивов среднего размера и один для больших массивов.
Массив же представляет собой единый массив с возможностью изменения размера, данные которого хранятся в буфере.
Вот диаграмма, иллюстрирующая сказанное.
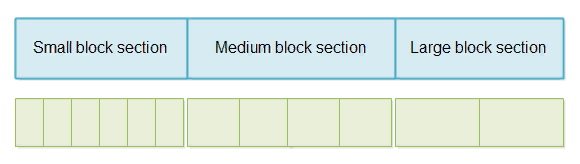
Из большого массива в буфер для каждого интервала размера сообщения (малый, средний, большой) мы следим за тем, чтобы массив не мог быть полностью заполнен сообщениями любого размера. Например, получение большого количества небольших сообщений не может занимать всю память и, следовательно, блокировать средние и большие сообщения. Аналогично, получение большого количества больших сообщений не может занимать всю память и блокировать сообщения среднего и малого размера.
Поскольку все сообщения начинаются как небольшие сообщения, если количество небольших массивов исчерпано, новые массивы не могут быть выделены, независимо от того, есть ли место в разделах среднего и большого массива или нет. Однако можно сделать небольшую секцию массива достаточно большой, чтобы вероятность этого была очень низкой.
По-прежнему возможно превращать небольшие сообщения в средние и большие сообщения, даже если раздел небольших сообщений используется полностью.
Варианты оптимизации
Возможной оптимизацией является использование только одного размера блока. Таким образом, иногда вновь выделенный блок может быть выделен сразу после блока, который необходимо расширить. В этом случае вам не нужно копировать данные из старого массива в новый. Вы можете просто "развернуть" блок, чтобы включить оба из двух выделенных блоков, и записать новые данные в расширенный блок, откуда был добавлен второй блок. Это экономит копирование всех данных массива, когда блок памяти может быть "расширен" в следующий последовательный блок.
Недостатком вышеупомянутой возможной оптимизации является то, что в тех случаях, когда невозможно расширить до следующего блока памяти, копирование данных все равно необходимо. Таким образом, у вас есть небольшие накладные расходы на проверку возможности расширения. Кроме того, если вы используете небольшой размер блока, вам, возможно, придется расширять блоки чаще, чем если бы вы использовали, например, малый, средний и большой размер блока.
Отслеживание свободных блоков
Большой массив внутри буфера разделен на три секции. Каждая секция разделена на более мелкие блоки. Каждый блок в каждом разделе имеет одинаковый размер. Блоки в разделе небольших сообщений имеют такой же небольшой размер блока. Блоки в разделе среднего сообщения имеют одинаковый средний размер блока. И блоки в разделе больших сообщений имеют такой же большой размер блока.
Когда все блоки в разделе имеют одинаковый размер, легче отслеживать используемые и неиспользуемые блоки. Вы можете просто использовать очередь, содержащую начальные индексы каждого блока. Для каждого раздела общего массива требуется одна очередь. Таким образом, одна очередь необходима для отслеживания свободных небольших блоков, одна очередь для бесплатных средних блоков и одна очередь для бесплатных больших блоков.
Выделение блока из любого из разделов может быть выполнено простым путем взятия следующего индекса начала свободного блока из очереди, связанной с нужным разделом. Освобождение блока выполняется путем помещения начального индекса обратно в соответствующую очередь.
В качестве очереди я использовал простую реализацию кольцевого буфера. Реализация, используемая в GitHub , называется QueueIntFlip.
Расширение при записи
Расширяемый массив будет расширяться сам по себе, когда вы будете записывать в него данные. Если вы попытаетесь записать в него больше данных, чем у него есть места в выделенном в данный момент блоке, он выделит новый, больший блок и скопирует все свои данные в этот новый блок. Затем освобождается предыдущий меньший блок.
Очистка массивов
Как только вы закончите с изменяемым размером массива, вы должны снова освободить его, чтобы его можно было использовать для других сообщений.
Использование буфера
Я хочу показать вам, как использовать ResizableArrayBuffer (из репозитория GitHub).
Создание ResizableArrayBuffer
Сначала вы должны создать ResizableArrayBuffer:
int smallBlockSize = 4 * 1024;
int mediumBlockSize = 128 * 1024;
int largeBlockSize = 1024 * 1024;
int smallBlockCount = 1024;
int mediumBlockCount = 32;
int largeBlockCount = 4;
ResizableArrayBuffer arrayBuffer =
new ResizableArrayBuffer(
smallBlockSize , smallBlockCount,
mediumBlockSize, mediumBlockCount,
largeBlockSize, largeBlockCount);
В этом примере создается ResizableArrayBuffer с небольшим размером массива 4 КБ, средним размером массива 128 КБ и большим размером массива 1 МБ. ResizableArrayBuffer содержит пространство для 1024 небольших массивов (всего 4 МБ), 32 средних массивов (всего 4 МБ) и 4 больших массивов (всего 4 МБ) - для полного общего размера массива 12 МБ.
Получение экземпляра ResizableArray
Чтобы получить экземпляр Resizablearray, вызовите метод getArray() ResizableArrayBuffer, например:
ResizableArray resizableArray = arrayBuffer.getArray();
В этом примере получается изменяемый размер массива наименьшего размера (ранее был установлен небольшой размер 4 КБ).
Запись в ResizableArray
Вы записываете в ResizableArray, вызывая его метод write(). Класс ResizableArray в репозитории GitHub содержит только один метод write(), который принимает ByteBuffer в качестве параметра. Однако добавить дополнительные методы write() самостоятельно должно быть довольно легко.
Например:
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
for(int i=0; i < 1024; i++){
byteBuffer.put((byte) i);
}
byteBuffer.flip():
int bytesCopied = resizableArray.write(byteBuffer);
В этом примере содержимое ByteBuffer копируется в массив (блок) ResizableArray. Значение, возвращаемое функцией write(), представляет собой количество байтов, скопированных из ByteBuffer.
Если ByteBuffer содержал больше данных, чем ResizableArray, ResizableArray попытается расширить себя, чтобы освободить место для данных в ByteBuffer. Если ResizableArray не может содержать все данные в ByteBuffer после расширения до максимального размера, метод write() вернет значение -1, и никакие данные не будут скопированы вообще!
Чтение из ResizableArray
Когда вы читаете из ResizableArray, вы делаете это непосредственно в общем массиве, который совместно используют все экземпляры ResizableArray. Изменяемый размер массива содержит следующее общедоступное поле:
public byte[] sharedArray = null;
public int offset = 0;
public int capacity = 0;
public int length = 0;
Поле SharedArray ссылается на общий массив, в котором все экземпляры ResizableArray хранят свои данные. То есть массив также хранится внутри ResizableArrayBuffer.
Поле смещения содержит начальный индекс в общем массиве, где этот ResizableArray хранит свои данные (назначенный ему блок).
Поле capacity содержит размер блока в общем массиве, назначенном этому экземпляру ResizableArray.
Поле длины содержит, какую часть назначенного блока фактически использует ResizableArray.
Чтобы прочитать данные, записанные в ResizableArray, просто считайте байты из
sharedArray[offset] to sharedArray[offset + length -1]
Очистка ResizableArray
Как только вы закончите использовать экземпляр ResizableArray, вы должны освободить его. Вы делаете это просто, вызывая метод free() в ResizableArray, например:
resizableArray.free();
Вызов free() заботится о возврате использованного блока в правильную очередь блоков, независимо от размера блока, выделенного для ResizableArray.
Вариации исполнения
Вы можете изменить дизайн моего ResizableArrayBuffer в соответствии с вашими потребностями. Например, вы можете создать внутри него более 3 разделов. Это должно быть довольно легко сделать. Просто посмотрите на код в репозитории GitHub и измените его.
#code #java #performance