Это один из самых мощных моих проектов за последнее время. Кроме того, что тема временных рядов сама по себе важна в специфике работы торговой компании, ещё было интересно закрепить навыки работы с широким спектром ML инструментов, от линейной регрессии до SARIMA.
Описание проекта
Компания заказчика собрала исторические данные о заказах такси в аэропортах. Чтобы привлекать больше водителей в период пиковой нагрузки, нужно спрогнозировать количество заказов такси на следующий час.
Требования и указания :
- Значение метрики RMSE на тестовой выборке должно быть не больше 48.
- Выполнить ресемплирование данных по одному часу.
- Проанализировать данные.
- Обучить разные модели с различными гиперпараметрами.
- Сделать тестовую выборку размером 10% от исходных данных.
- Проверить данные на тестовой выборке и сделать выводы.
Описание данных. Данные предоставлены в файле /datasets/taxi.csv. Количество заказов находится в столбце 'num_orders'.
Содержание
- 0.1 Описание проекта
- 1 Подготовка
- 1.1 Ресемплирование
- 2 Анализ
- 2.1 Скользящее среднее
- 2.2 Тренд и сезонность
- 2.3 Стационарность рядов
- 2.4 Разности временного ряда
- 2.5 Обработка выбросов
- 2.6 Вывод по анализу данных
- 3 Обучение
- 3.1 Методы генерации признаков и разбивки данных
- 3.2 Линейная регрессия
- 3.2.1 Модель 1 - только лаги и временные признаки
- 3.2.2 Модель 2 - добавили дифференциальный признак
- 3.2.3 Модель 3 - на основе фич независимых от таргета
- 3.2.4 Модель 4 - скользящее среднее и добавление количества лагов
- 3.2.4.1 Ограничение горизонта прогноза
- 3.2.4.2 Оценка наилучшей линейной модели на кросс-валидации
- 3.3 Выводы по линейной регрессии
- 3.4 Модель prophet
- 3.4.1 Приведем датасет к нужному виду для его последующего анализа в библиотеке etna
- 3.4.2 Подготовка датафрейма для модели prophet
- 3.4.3 Первая модель prophet
- 3.4.4 Модели prophet с разными параметрами
- 3.4.5 Выводы по модели prophet
- 3.5 Модель Градиентного бустинга
- 3.5.1 Подготовка датасета в нужном виде
- 3.5.2 Градиентный бустинг первая модель с параметрами по умолчанию
- 3.5.3 Подбор параметров для градиентного бустинга
- 3.5.4 Градиентный бустинг модель с наилучшими параметрами
- 3.5.5 Вывод по модели градиентного бустинга
- 3.6 Модель SARIMA
- 4 Тестирование
- 4.1 Лучшая модель градиентного бустинга на тестовых данных
- 5 Общий вывод
- 6 Чек-лист проверки
Анализ данных
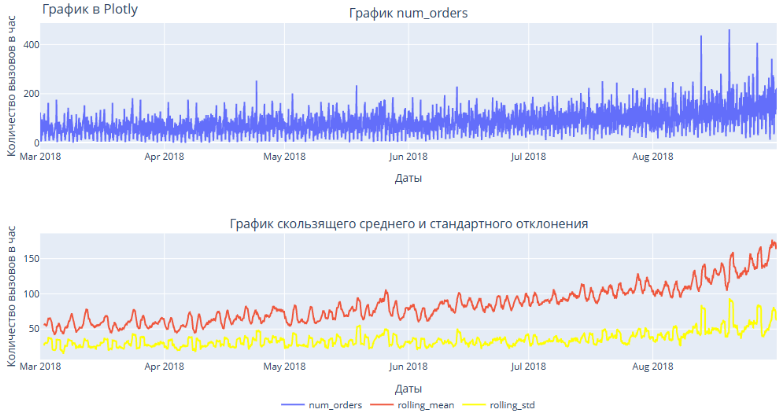
Первоначальные данные приведены с шагом 10 мин. В среднем видим 14 вызовов за период. Максимум 119. Самое частое значение 13 вызовов за период. В результате ресемплирования данные аггрегированы с шагом 1 час. В среднем видим 84 вызовов за час. Стандартное отклонение 45 вызовов. Максимум 462.Самое частое значение 78 вызовом за период.
Построены графики скользящего среднего и скользящего стандартного отклонения с окном 24 часа. На скользящем среднем более заметен незначительный положительный тренд.
Построены графики тренда, сезонности, недельной сезонности и график шума. В рамках анализа сезонности очевидна дневная периодичность. Также наблюдается незначительный положительный тренд.
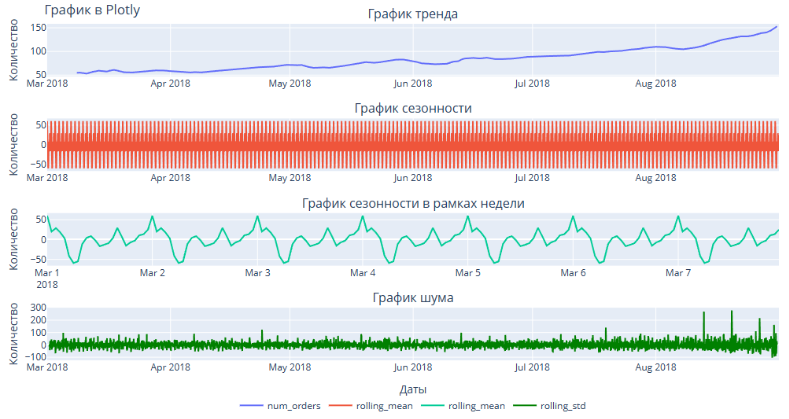
Анализируя построенные графики, можно предположить, что стационарным является только график сезонности. На графике тренда со временем меняется среднее значение, а на графике остатков изменяется дисперсия. Но однозначные заключения по графикам сделать сложно, поэтому ряды проверены на стационарность по критерию Дики-Фуллера.
Тем не менее проверка на стационарность по критерию Дикки-Фуллера показала, что ряд num_orders стационарен!
Созданы дополнительные поля разности. Проверка Дикки-Фуллера показала, что все они стационарны. При анализе графиков разности можно отметить лишь незначительное изменение дисперсии рядов и отсутствие тренда. Больше всего графики рядов разности похожи на график шума.
Нюансы обработки выбросов для временных рядов
Перечень выбросов в данном проекте определен с помощью стандартной диаграммы размаха
Судя по графику выше, большинство этих значений вполне естественно вписываются во временной ряд. А в список выбросов они попали из-за того что находятся в конце временного ряда, а у нас есть положительный тренд. Поэтому принято решение найденные выбросы не удалять.
На будущее, с выбросами во временных рядах нужно действовать деликатнее.
Если есть супер продажи, то ведь этому есть причины.
По хорошему, тут надо выяснить, что это за дни. например понедельник. Взять несколько понедельников до и после этого значения и рассчитать медиану. Подставить вместо большого значения медиану, зафиксировать разницу. Тем самым решили две задачи:
- убрали выброс
- занесли в базу идентификатор выброса: дата - причина ( спросить у коммерсантов)
Другая ситуация: А может быть обнаружили несколько пятниц с повышенным спросом продаж. Скажем лето, белые ночи в Питере....
Тогда это не выброс, а реальная история продаж. И её нельзя вот так вот "убивать".
И ещё момент: когда есть тренд, то гистограмма и ящик с усами - так себе инструменты(они не для этого). А вот если анализировать остатки, то тут да, очень и очень понадобятся эти графики.
Метод генерации признаков
Обучение моделей
В рамках прогнозирования временного ряда подготовлены модели линейной регрессии, prophet, градиентного бустинга и SARIMA.
Модели линейной регрессии
При прогнозировании временного ряда с помощью линейной регрессии проанализировано влияние различных критериев на результаты оценки. Были опробованы разные методы подготовки выборок данных. Сначала разбивка на train valid test, потом генерация дополнительных признаков и наоборот. Сильного влияния на точность это не оказало. Подготовлены несколько вариантов дополнительных признаков.
1. Только 1 лаг и временные признаки. В данной модели использовались признаки принадлежности по времени, и один лаг. Скользящее среднее и дифференциальный признак не использовались. Получены приемлемые результаты по точности. RMSE на валидационной выборке равно 40.96. Используемые признаки показали свою пригодность. Для увеличения точности можно добавить количество лагов. В данном варианте прогнозирования сначала провели разбивку данных, и уже потом сгенерили фичи. Вариант показал свою применимость.
2. В варианте 2, по сравнению с предыдущим мы добавили дифференциальный признак (таргет минус лаг). Посмотрим как изменится результат. На выходе суперточный результат. RMSE стремится к нулю. Но так делать не нужно. Результат такой модели нельзя считать объективным. Можно сделать вывод, что утечку таргета даёт дифференциальный признак. Поэтому в дальнейшем прогнозировании от этого признака отказываемся.
3. В третьем варианте использованы только зависимые от времени признаки. В результате оценки модели на критериях не зявисящих от target, мы получили на валидадионных данных вполне адекватные значения показателя RMSE = 46. Но при взгляде на график видно, что прогноз далек от идеала, и выдаёт значение близкое к среднему. Для проверки была проведена проверка модели на адекватность. При постоянном прогнозе среднего значения RMSE = 58.
4. Для очередной модели сначала создали фичи, а потом разделили датафрейм на train, valid, test. Плюс, в данном варианте используем признак скользящего среднего, с глубиной 24, а также 24 признака лага. Дифференцированные признаки не используем, т.к. через них происходит утечка таргета. Модель показала хороший результат. На валидационной выборке RMSE = 34.22. На графиках виден приемлемый прогноз. Поэтому делаем вывод о наибольшей точности модели благодаря выбранным признакам. Также можно сделать вывод, что способ разбивки данных после генерирования фич показал свою пригодность.
Реализована наилучшая модель на валидационной выборке, используя кросс-валидацию с условием TimeSeriesSplit. На выходе кросс-валидация с условием TimeSeriesSplit показала отличный результат, RMSE = 27.16 На входе данной модели были даны объединённые выборки train и valid. Увеличение выборки поспособствовало улучшению результата.
Библиотека ETNA
Для модели prophet библиотеки etna была подготовлена отдельная таблица формата TSDataset. Для отработки прогнозирования нескольких рядов, кроме целевого признака был подготовлен дифференцированный признак разности таргета и лага_1.
При работе с библиотекой etna исходный файл должен содержать определенные поля. В т.ч. поле segment. Таким образом можно работать одновременно с большим количеством рядов. Каждый сегмент это отдельный ряд. Модель может оценивать например ряды по разной продукции. В данном случае приводится пример работы с двумя разными таргетами.
На приведенных графиках нам интересна корреляция ряда row. Видим снижение корреляции начиная со второго лага по четвертый, и повышение с 20 по 24й. Можно сделать заключение, что при генерации признаков есть смысл брать 24 лага. Этот момент объясняется дневной сезонностью, и был эффективно применен выше в линейной регрессии.
Библиотека ETNA модель prophet
На первой модели получено RMSE = 35. На графике видны неудовлетворительное совпадение прогноза с фактом. Далее были реализованы несколько моделей с разными гиперпараметрами, выбрана лучшая и проанализировано воздействие гиперпараметров на результат.
Найлучшей метрики RMSE = 33.69 удалось достичь на гиперпараметрах:
- growth = 'linear',
- yearly_seasonality = False,
- additional_seasonality_params = [{'name': 'hour', 'period': 1, 'fourier_order': 50}],
- daily_seasonality = False,
- uncertainty_samples = 0,
- weekly_seasonality = False
Таким образом, ключевыми гиперпараметрами являются выбор модели growth = 'linear' (при выборе flat показатели ухудшились) и дополнительные параметры сезонности additional_seasonality_params = [{'name': 'hour', 'period': 1, 'fourier_order': 50}]
Модели градиентного бустинга
Для модели Градиентного бустинга подготовлен датасет и соответствующие выборки train, valid, test. Из признаков времени убран номер месяца, т.к. в анализируемом ряде представлены данные на 6 месяцев, и признак будет неинформативен для прогноза. Номер месяца может быть полезным для данных минимум за 2-3 года.
В начале, была подготовлена первая модель с гиперпараметрами по умолчанию. Получили RMSE = 48.05. Далее проведен подбор оптимальных гиперпараметров с помощью GridSearchCV. Для учёта нюансов работы кросс-валидации с временным рядом был применён TimeSeriesSplit с разбивкой датасета train на 8 частей. Логика такая, train 8 частей, valid 1 часть, и test 1 часть. Оптимальные гиперпараметры n_estimators=500, depth=5.
Полученная RMSE модели на валидационной выборке равна 30.67 Это наилучший параметр из всех ранее применённых моделей.
Модели SARIMA
На моделях SARIMA в рамках данного проекта получить значимые результаты не удалось. Вероятно это связано с некорректным подбором гиперпараметров и низким быстродействием персонального компьютера. Модель считает долго и времени на эксперимент не остаётся. На бОльших мощностях можно было бы более оперативно подобрать нужные гиперпараметры.
Итоговый результат
Таким образом на валидационных данных наилучший результат показал Градиентный бустинг с RMSE = 30.67. Тестирование данной модели на тестовых данных позволяет получить RMSE = 38.38, что полностью соответствует поставленной задаче.
Куда развиваться дальше
Немного теории по остаткам ряда. Это факт минус прогноз (по сути - ошибка ряда). И вот остатки должны быть как минимум нормальными... (см.свойства). И вот если с остатками всё ОК. (они нор мальные), то можно применять "золотое" правило 3-х сигм. Т.е. посчитать стандартное отклонение. И вот если посчитать среднюю ошибку и отложить от неё +- 3 стандартных отклонения, то это и будет интервальный прогноз.
Тут много ещё что можно сказать по самой теме...
Если будет возможность однозначно интересно посмотреть разные практические истории вот здесь:
https://ibf.org/knowledge - институт бизнес-прогнозирования.
Там и статьи можно накопать, и методы посмотреть...
Есть классический труд (он НЕ ML, а исключительно на эксель). Но для понимания сути временных рядов - то, что надо:
УИЧЕРН "Бизнес-прогнозирование"
Идеологически по системе прогнозирования, интересно почитать
ТОМАС УОЛЛАС, Р. СТАЛЬ "планирование продаж и операций" SO&P
Ещё по анализу остатков. Обычно ещё смотрят три свойства:
1) Нормальность (график гистограмма)
2) Постоянство дисперсии (разброса) ошибки на всём протяжении модели (график скатерплот остаткков и предсказанных значений)
3) автокореляция остатков (график автокорреляции)
Если всё ок - говорят, что модель адекватна (не смотря на метрику).
Если нарушен 1 и 3 свойство - модель можно улучшить.
Если нарушен 2 модель использовать нельзя.
Ниже на картинке хорошие-плохие остатки
Ещё момент, столкнулся с тем, что плотли - тяжеловат для обучения. При загрузке файла не всегда отображаюся ранее построенные графики. В следующих проектах лучше буду использовать сиборн.