О циклах (операциях) чтение-модификация-запись в книгах по программированию и на лекциях в ВУЗах обычно не рассказывают. По вполне понятной причине - этот вопрос больше относится к архитектуре ЭВМ, а не к прикладному программированию. Редко затрагивают эту тему и в курсах системного программирования, что уже не совсем правильно.
Но для тех, кто пишет программы работающие с регистрами оборудования напрямую, понимание, что это такое, и как работает, уже важно. Да и системным программистам лишним не будет. Более того, иметь некоторое представление полезно и прикладным программистам.
У новичков возникает не мало вопросов, прямо или косвенно, связанных с циклами чтение-модификация-запись. Поэтому попробуем разобраться поподробнее. Причем сразу с нескольких сторон, начиная с обычного прикладного программирования и заканчивая архитектурными особенностями ЭВМ.
Что такое цикл (операция) чтение-модификация-запись?
На самом деле, с этим сталкивался любой программист, в любой программе. Исключения если есть, то чрезвычайно редки. Не верите? Тогда смотрите
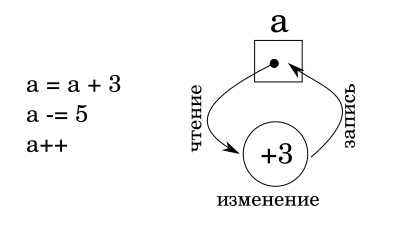
Не правда ли, просто и очень банально? А раз так, может и говорить то не о чем? Не спешите с выводами! За кажущейся банальностью скрывается много интересного и важного. И мы скоро это увидим.
Итак, с точки зрения программирования прикладного, на первый взгляд, цикл чтение-модификация-запись возникает, когда переменная появляется и с левой, и с правой стороны оператора присваивания. То есть, мы получаем значение (содержимое) переменной, изменяем его, и снова помещаем на тоже самое место. Все верно? Мы ничего не упустили?
Упустили! Я не случайно на иллюстрации использовал очень простые выражения. Эти выражения нельзя разбить на более мелкие. Не смотря на то, что в каждом выражении две операции, первая арифметическая, вторая операция присваивания (в последнем примере присваивание тоже есть, но оно неявное), сами выражения являются по сути атомарными. Во всяком случае, с точки зрения языка высокого уровня.
Для примера, вот такое выражение
a = a + 4 * b - c
уже не является атомарным, так как его можно разбить на несколько отдельных выражений. Но что можно сказать вот о таком выражении?
a = sin(a)
Атомарное ли оно? Ведь с точки зрения языка высокого уровня его нельзя разбить на несколько отдельных, более простых, выражений. Но давайте вспомним, что функция sin является библиотечной, причем может иметь довольно сложную реализацию. Причем это верно даже в том случае, если данная функция определена на уровне самого языка. Исключения бывают, например, процессор может иметь машинную команду вычисления полного синуса. Тем не менее, в общем случае, такое выражение не будет атомарным.
Есть и еще одно условие, цикл (операция) чтение-модификация-запись не может быть прерван, даже на аппаратном уровне. На самом деле, не каждое атомарное выражение обладает свойством непрерываемости. Мы это сегодня рассмотрим, но чуть позже.
Итак, цикл, или операция, чтение-модификация-запись выполняет атомарно и непрерываемо, как единую операцию, последовательность получения значения переменной, его изменения, помещения результата обратно в переменную.
Прикладной программист далеко не всегда может управлять атомарностью на машинном уровне, да и запрещать прерывания может не позволить операционная система. Поэтому этот вопрос обычно и не затрагивается при обучении языку программирования или в курсе прикладного программирования.
Тогда почему прикладному программисту полезно иметь хотя бы небольшое представление о цикле чтение-модификация-запись? Скоро и это узнаем.
Пара слов о транзакциях
Транзакции позволяют объединить в одно целое несколько последовательных операций. Однако, называть транзакцию атомарной можно только с точки зрения высокого уровня. Например, с точки зрения пользователя базы данных.
На более низких уровнях транзакция все таки распадается на отдельные операции. Более того, транзакция может быть прервана для выполнения операции более высокого приоритета. Но при этом действительно гарантируется, что будут выполнены все составляющие транзакцию операции.
А что на уровне процессора?
Я сказал, что прикладной программист далеко не всегда может управлять атомарностью. Пришло время узнать, в чем причина. Для этого нужно спуститься на более низкие уровни. Но не пугайтесь, глубоких знаний о работе процессора не потребуется. Но если вы хотите разобраться получше, то можете предварительно почитать статьи
Микроконтроллеры для начинающих. Часть 2. Процессор микроконтроллера
Микроконтроллеры для начинающих. Часть 3. Процессор микроконтроллера. Тактирование и синхронизация.
Не секрет, что процессор исполняет не выражения языка высокого уровня, а машинные команды. Но архитектура процессора может быть разной, и машинные команду могут быть разными. А значит, и результат компиляции выражения
var = var + 5
может быть разным, и ход выполнения программы. Давайте посмотрим на пару типовых ситуаций.
Аккумуляторная и стековая архитектура
В процессорах аккумуляторной архитектуры все операции выполняются только с содержимым специального регистра - аккумулятора. Поэтому нужно сначала загрузить в аккумулятор содержимое ячейки памяти (ОЗУ) соответствующее переменной var, затем выполнить операцию сложения содержимого аккумулятора с константой, и только потом можно записать содержимое аккумулятора обратно в память
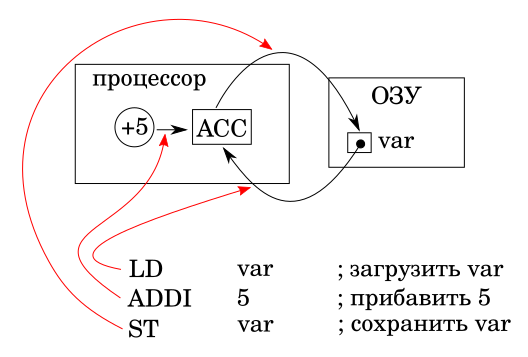
АСС это регистр аккумулятор. Три машинные команды. Значит, на уровне процессора наше выражение уже не будет атомарным. В отличии от языка высокого уровня. Но дело в том, что понятия языка высокого уровня для машины ничего не значат.
То есть, на данной машине операция увеличения переменной на 5, из нашего примера, и все подобные операции, не будет атомарной. И повлиять на это программист не может.
Выполнение машинной команды, во всяком случае, для большинства процессоров, прервано быть не может. Экстремальные случаи, вроде отключения питания в середине выполнения команды, рассматривать сегодня не будем. Могут возникать нюансы и для процессоров с конвейеризацией выполнения команд, особенно, многоуровневой. Но настолько глубоко мы сегодня погружаться не будем.
Если возникает запрос прерывания, то он будет обработан и исполнен между выполнением двух последовательных команд. В нашем случае, таких мест два. Первое, между командами LD и ADDI. Второе, между командами ADDI и ST. Таким образом, на уровне машины, наше выражение, атомарное для языка высокого уровня, будет не только неатомарным, но оказывается и прерываемым.
Конечно, можно запретить прерывания перед вычислением выражения и разрешить после. Если непрерываемость действительно важна. Но это должен в явном виде предусмотреть программист. В том числе, прикладной. Будут это вызовы специальных процедур, использование предоставляемых операционной системой возможностей, использование дополнительных атрибутов при объявлении переменной, значения не имеет.
Основанная на стеке архитектура ничего принципиально не меняет. Только вместо регистра-аккумулятора теперь будет использоваться набор регистров образующих стек. Да, выглядеть это будет немного иначе
Да, другие команды, причем их стало на одну больше. И точек, в которых может быть обработано прерывание стало больше. Но принципиальных отличий нет. По прежнему наше выражение на уровне процессора не является атомарным.
Кроме того, нам это скоро понадобится, обратите внимание, что с точки зрения ОЗУ, при вычислении этого выражения, у нас есть две раздельные операции. Первая чтение, вторая запись. И эти операции выполняются разными, разнесенными во времени машинными командами.
Архитектура с регистрами общего назначения и многоадресными командами
В таких процессорах есть набор равноправных, или почти равноправных, регистров. А машинные команды могут быть не только одноадресными, когда в команде можно указать только один адрес ячейки памяти, но многоадресными. Это позволяет, в частности, выполнять арифметические операции с двумя ячейками памяти не используя регистры в явном виде.
И теперь у нас будет совсем иная ситуация. Не смотря на то, что для выполнения операции по прежнему требуется загрузить в процессор из памяти содержимое ячеек памяти. АЛУ по прежнему находится в процессоре
ALU это арифметическо-логическое устройство, а не регистр. Об устройстве АЛУ можете почитать статьи
Элементы ЭВМ. АЛУ - арифметико-логическое устройство. Часть 1
Элементы ЭВМ. АЛУ. Часть 2. Внутренний мир
На первый взгляд, ничего особо не изменилось. Но обратите внимание, что теперь нам потребовалась всего одна машинная команда. То есть, теперь у нас и на уровне процессора вычисление нашего простого выражения является атомарной и непрерываемой операцией.
Да, на еще более низком уровне, на уровне микропрограммной или схемотехнической реализации процессора, операция все равно распадается на те же самые основные этапы. Но на уровне процессора мы уже не можем разбить операцию на более мелкие этапы. А выполнение команды прервано быть не может.
И этот пример показывает влияние архитектуры машины (не только процессора), в том числе, на достаточно высокоуровневые понятия. Такие, как атомарность операции. И показывает, что языки высокого уровня не всегда избавляют от необходимости учитывать, на какой машине будет выполняться программа.
Влияние на прикладных программистов
Когда начинающие программисты изучают многопоточное или многозадачное программирование, их обязательно знакомят с правилами работы с данными, которые используются одновременно в нескольких параллельно выполняющихся потоках. Они изучают и способы синхронизации потоков, и примитивы синхронизации.
Но не всегда система, которая кажется однопоточной, является таковой на самом деле. А значит, начинающий программист просто может не заметить подвоха. Особенно, если он еще не добрался до изучения параллельно работающих процессов.
Не воспринимайте данный раздел как ностальгию по MS-DOS или воспоминания и правилах разработки программ для этой системы. Речь идет о том, не каждая система, которая кажется однопоточной, является таковой на самом деле. И не более того.
Давайте рассмотрим пример такой системы из не столь далекого прошлого
Да, это та самая MS-DOS, причем даже самых первых версий, когда и речи не шло о резидентных программах. И которая работала на однопроцессорных машинах. И очень многие считали, что программа пользователя, та самая прикладная программа, монопольно владеет и машиной, и системой.
Это во многом действительно так. Но при штатной работе процессы драйверов устройств работали "параллельно" программе пользователя. Слово параллельно я не случайно взял в кавычки. Истинного параллелизма конечно не было, но программа пользователя могла быть прервана в любой момент для выполнения процесса драйвера.
Переменные, которые хранили в MS-DOS текущие дату и время располагались в памяти ОС, но не соответствовали никаким аппаратным регистрам оборудования. Для чтения и изменения даты и времени в системе были предусмотрены специальные функции, которые нужно было вызывать. Но кого это в те времена останавливало от прямой работы с памятью ОС?
Начинающий программист, которого уже успели предупредить, что с аппаратными регистрами нужно работать очень осторожно, но который еще не сталкивался с работой с разделяемой памятью, может посчитать, что дату и время можно изменять не через функции ОС, а напрямую. Так же быстрее... Опытный программист конечно заметит подвох и не забудет запретить прерывания на время изменения, но новичек может просто не знать про это.
Да, этот вопрос касается атомарности доступа. Но атомарность, правда немного "по касательной", относится и к теме сегодняшней статьи. Выражение, например
day -= 7; /* на неделю назад */
кажется таким простым и атомарным, циклом чтения-модификация-запись, совершенно безопасным. А эта атомарность после компилятора может стать совсем не атомарной.
Обратите внимание, что модификатор volatile для переменной day в этом случае не поможет. Так как он не обеспечивает атомарности доступа.
Да, в Intel 8086 есть команды сложения и вычитания работающие с памятью напрямую. И такой "возврат на неделю назад" может быть реализован всего одной командой. Вопрос лишь в том, использует ли эту команду компилятор.
Конечно, MS-DOS давно в прошлом. Но машины и сегодня бывают самые разные. И прикладные программисты могут писать программу не только для настольного ПК или сервера, но и для встраиваемой системы или контроллера.
Влияние на организацию работы ОЗУ
Давайте ненадолго отложим программные аспекты. К влиянию на системное программирование вернемся чуть позже. А пока коснемся архитектурных вопросов построения ЭВМ.
Вспомним ферритовую память, о которой рассказывалось в статье
Ферритовая память. Как это работало? Просто о сложном.
Характерной особенностью работы такой памяти было то, что операция чтения приводила к разрушению хранящейся в ячейке информации. Поэтому после чтения всегда выполнялся цикл восстановления информации, что требовало времени. Цикл восстановления мог выполняться уже после окончания чтения, параллельно работе собственно процессора. Но это не всегда позволяло повысить быстродействие машины, так как частота обращения к памяти все равно ограничивалась и циклами восстановления. Да и на потребляемой мощности такие циклы в любом случае сказывались.
Однако, цикл чтение-модификация-запись позволяет исключить необходимость в цикле восстановления, так как информация все равно будет сразу перезаписана. Давайте рассмотрим этот вопрос чуть подробнее. При этом считывание из памяти программного кода во внимание принимать не будем.
Раздельные циклы чтения и записи
Вспомним наш пример для аккумуляторной архитектуры процессора. Чтение памяти выполнялось командой LD, а запись ST. Поскольку между этими командами могло быть, в общем случае, выполнено любое количество иных команд, нельзя сделать каких либо допущений и связанности между этими двумя командами.
Это означает, что команда LD будет выполнять цикл чтения памяти с последующим обязательным циклом восстановления. Команда ST будет обязательно выполнять цикл стирания (чтения без использования результата) с последующим циклом записи. Таким образом, нам потребуется 4 полных цикла обращения к памяти. Не считая времени выполнения операции процессором и считывания кодов команд.
Если цикл восстановления выполняется параллельно работе процессора, то потери времени будут меньше, но цикл стирания все равно никуда не денется.
Здесь нет, и не может быть, так как операция не атомарная, цикла чтение-модификация-запись.
Сокращенные и объединенные циклы чтения и записи
Но если у нас процессор классической архитектуры с РОН, то и чтение, и запись, будут выполняться одной командой ADD. Здесь уже в явном виде есть цикл чтение-модификация запись. И это устраняет необходимость в циклах восстановления и стирания.
Правда при этом процессор должен в явном виде запросить выполнение цикла чтение-модификация-запись, а не раздельных циклов чтения и записи. И это действительно возможно, так как при декодировании команды будет видно, что источник и приемник данных при выполнении команды один и тот же.
Таким образом, если учитывать циклы чтение-модификация-запись при проектировании процессора и ОЗУ, можно повысить быстродействие машины в целом. Хоть и выигрыш будет зависеть, в том числе, от выполняемых команд.
Ферритовая память тоже в прошлом. Хотя учет циклов чтение-модификация-запись при работе с памятью может быть полезен и сегодня. Например, при проектировании многоуровневой кэш памяти.
Влияние на системные шины и магистрали
Но только памятью польза от учета циклов чтение-модификация-запись не ограничивается. Во всех машинах есть одна или несколько шин/магистралей данных. Шины могут выделенными, например, шина памяти в однопроцессорной системе. Шины могут быть разделяемыми, например, шина для обмена с внешними устройствами.
В простейшем случае, на такой шине может быть только один задатчик или ведущий. Сегодня такой ведущий чаще называется master. В таком случае он полностью определяет работой шины и никаких конфликтов не возникает. В большинстве случаев, таким ведущим является процессор. Иногда не напрямую, а через контроллер шины.
Но в общем случае, на шине может быть несколько ведущих. Причем это не обязательно многопроцессорная машина, таким ведущим может выступать и внешнее устройство, например, использующее канал ПДП. И вот тут то и возникает конкуренция за право использования шины.
Решает, кто будет использовать шину в течении очередного цикла, специальный контроллер (модуль) - арбитр шины. Как устроен и работает арбитр шины нам сегодня не важно. Возможно, об этом будет отдельная статья. Сегодня нам важно, что каждый доступ к такой шине будет состоять из нескольких этапов
- Запрос цикла доступа у шине
- Ожидание разрешение доступа от арбитра шины
- Установка на шине адреса. Если будет выполняться передача данных, то выставление на шине передаваемых данных. Выдача по шине команды (операции).
- Ожидание окончания выполнения операции. Если выполнялось чтение, то считывание выставленных на шине данных как результата операции.
- Освобождение шины. Управление шиной возвращается арбитру.
Хорошо видно, что если доступ к шине осуществляется двумя разными командами, как в примере с ферритовым ОЗУ, то каждый раз будут выполнены все эти этапы.
Но если учитывать циклы чтение-модификация-запись, когда при выполнении одной команды выполняется и чтение, и запись, причем по одному и тому же адресу, то можно повысить быстродействие исключив часть этапов
При этом шина не освобождается после окончания цикла чтения, а остается занятой. В данном случае, на время выполнения собственно сложения. Это увеличивает возможное время ожидания освобождения шины для другого ведущего. Но повышает общую производительность шины.
Разумеется, циклы чтение-модификация-запись должны поддерживать не только процессоры, но и другие устройства на шине. Даже те, которые не могут работать как ведущие.
Поэтому польза от учета циклов чтение-модификация-запись была не только в прошлом (когда деревья память была ферритовой), но и сегодня.
Когда его совсем не ждешь...
Давайте вернемся к программированию, но и про архитектурные особенности забывать не будем.
Еще в самом начале статьи мы рассматривали примеры именно изменения значения переменной (ячейки памяти). Присваивание переменной некоего значения в чистом виде, без учета начального значения этой переменной, очевидно, потребует только цикла записи, что темой сегодняшней статьи не является.
Но действительно ли это всегда так? Оказывается, далеко не всегда! Давайте посмотрим на работу с переменными размером в один бит. Такая возможность есть не во всех языках программирования высокого уровня. Более того, команды для работы с отдельными битами, а не с байтами или словами, есть не у всех процессоров.
Тем не менее, в языке С (и С++) такая возможность есть. Да и у многих процессоров тоже. А значит, посмотреть, как это работает, будет полезно.
Адресация отдельного бита встречается редко, например, она есть в MCS-51. Но это мы сегодня не будем рассматривать. Мы рассмотрим абстрактный процессор, который может ориентирован на работу с байтами. При этом процессор имеет команды установки, сброса, проверки состояния, инверсии, отдельно взятого бита в составе байта. Адрес бита при этом задается как адрес байта и номер бита в байте. Это достаточно типовой случай.
Отсутствие прямой адресации отдельного бита определяется не только архитектурой процессора, но и архитектурой памяти. Есть влияние и шины, или системной, или памяти, если она отдельная. Но это влияние уже незначительное.
Давайте посмотрим на простой пример
bit var;
var=1; /* Установить бит */
Как именно объявлено, что var это бит, не важно. Это может быть и такое вот специальное ключевое слово, или объявление битовых полей в структурах С, или какой либо иной способ. Но нам важно, что установка этого бита внешне выглядит как простое присваивание значения переменной. И, на первый взгляд, должно сводиться только к операции записи.
Пусть процессор имеет машинную команду BIS (BIt Set), которая может работать как с одним из регистров процессора, так и с байтом памяти напрямую. Если компилятор разместил наш бит в переменной _b_fld_, в бите номер 3, то выполнение присваивания может осуществляться такой командой
BIS _b_fld_ , 3 // установить бить 3 в байте _b_fld_
Возможно, вы удивитесь, но эта команда приведет к циклу чтение-модификация-запись, а не просто к записи.
Мы не сможем никак добраться до отдельного бита не загрузив в процессор весь байт, который и содержит наш бит. При этом не обязательно использовать явный программно-адресуемый регистр, будет использован внутренний регистр АЛУ. В нем и будет установлен в "1" наш бит, после чего содержимое регистра и будет передано в память.
Так что и простое присваивание может привести к выполнению цикла чтение-модификация-запись. И это может привести к неожиданным, и неприятным, побочных эффектам.
Вот теперь мы можем коснуться и системного программирования.
Влияние на системное программирование
Я не буду рассматривать реализацию общесистемных функций. Мы поговорим о программах работающих с оборудованием напрямую. В большинстве случаев, это будут драйверы устройств. Но не только.
Если внешнее устройство подключено к системной шине с разделяемым доступом, как мы уже видели ранее, можно повысить быстродействие явно отработав цикл чтение-модификация-запись. Процессор может это сделать автоматически, если его декодер команд способен определить, что команда действительно будет выполнять такой цикл.
Если же процессор не может сделать это самостоятельно, ему может помочь системный программист, который или использует специальную команду, или префикс команды. Если, конечно, таковые существуют. Или выдать соответствующий сигнал на контроллер шины. Все зависит от конкретной реализации машины. Разумеется, системный программист должен знать и понимать, как работает не только процессор и ОС, но и машина в целом.
Но это еще не все. Внешнее устройство может подключаться к одному из портов машины. И это верно не только для микроконтроллеров. Рассмотрим этот вопрос немного подробнее.
Порт, будем считать его портом ввода-вывода, причем способ его подключения в машине нас интересовать не будет, является двунаправленным. Направление передачи данных определяется выполняемой операцией.
При записи информация передается из машины (от процессора, шины, и т.д.) во внутренний регистр порта, где и хранится до следующей записи. Передачей данных с выходов регистра порта во внешний мир (на подключенное устройство) управляет отдельный регистр разрешения работы выходов, который являются частью порта и доступен по собственному адресу. При чтении информация передается с внешних выводов порта, а не из регистра порта, в машину.
То есть, мы не можем прочитать записанные в порт данные, мы можем прочитать только фактическое состояние выводов порта. Регистр DIR разрешает или запрещает передачу данных соответствующего разряда порта к внешнему устройству. Если передача разрешена, то соответствующий разряд работает как выход. Если запрещена, то как вход.
Если вы видите сходство с портами ввода-вывода микроконтроллеров, то не ошибаетесь. Но не стоит считать, что такое решение свойственно только микроконтроллерам. Подобные порты могут использоваться и в других машинах. Возникает вопрос, как это связано с темой сегодняшней статьи?
А связь прямая. Предположим, что у нас есть внешний АЦП имеющий вывод управления преобразованием. Логическая "1" на этом выводе начинает преобразование. После окончания преобразования АЦП устанавливает на этом выводе "0". Этот управляющий вывод подключен к одному разряду нашего порта (start_adc). К другому разряду (led) подключен светодиод, который используется для индикации какого либо состояния.
В программе мы переключаем вывод start_adc для работы в режиме вывода. Выполняем различные настройки. После чего запускаем преобразование выполнив
start_adc=1;
Переключаем вывод start_adc в режим входа и сбрасываем бит выполнив
start_adc=0;
Затем включаем индикацию выполнив
led=1;
Что может пойти не так? Давайте вспомним, что включение индикации это установка бита. А значит, вместо цикла записи будет выполнен цикл чтение-модификация запись. Если преобразование в АЦП еще не закончено, в прочитанном из порта значении бит start_adc будет установлен в "1". И в таком состоянии будет записан обратно в порт.
Это не приведет к проблемам, так как не отразится на состоянии вывода, он в режиме входа. Но в регистре порта информация будет искажена! Мы сбросили бит, а он снова оказался установлен! Мы этого не делали, но вмешался неявный цикл чтение-модификация-запись.
Далее мы ожидаем завершения преобразования опрашивая бит start_adc. Это порождает циклы чтения, которые не изменяют содержимого регистра порта. Когда бит окажется сброшенным, преобразование завершится и мы можем обрабатывать результат.
Пока нет никаких видимых последствий. Но в следующий раз, когда мы переключим start_adc в режим выхода, сразу запустится преобразование в АЦП. До его явного запуска установкой бита. Чего мы совсем не ожидаем, ведь мы собственноручно сбросили бит! А это уже явное проявление ошибки, которое может привести и к ошибочному результату.
И это ошибка именно программиста, скорее всего системного, который и разрабатывает драйвер такого АЦП. И возникла она или по невнимательности, или из-за непонимания того, как работают, и когда возникают, циклы чтение-модификация-запись.
А всего лишь нужно было учесть, что порт это не переменная в памяти, а аппаратный регистр, со своей спецификой работы. Что бы исключить циклы чтение-модификация-запись нужно ввести дополнительную буферную (рабочую) переменную, которая будет содержать точную копию состояния порта (за чем тоже придется следить). И все битовые операции нужно проводить с этой переменной, записывая в порт весь байт целиком.
Заключение
Мы кратко, в самых общих чертах, рассмотрели не самую простую для начинающих программистов и системотехников тему. За кадром осталось очень многое. Потому что это очень обширная тема, которая затрагивает и схемотехнику, и архитектуру ЭВМ, и схемотехнику внешних устройств.
Надеюсь, что теперь у вас появилось представление, что такое чтение-модификация-запись, и почему это важно. Если с чем то не согласны, что то осталось неясным, заметили ошибку - пишите в комментариях. Обсудим.