
Как понять причину неполадок в работе AI модели, не вдаваясь в сложности внутреннего механизма работы? Один из способов реализуем в этой статье.
В качестве площадки для экспериментов будем использовать сгенерированный ранее набор данных для предсказания расходов людей по их доходам и размерам дотаций из городского бюджета (подробнее здесь):
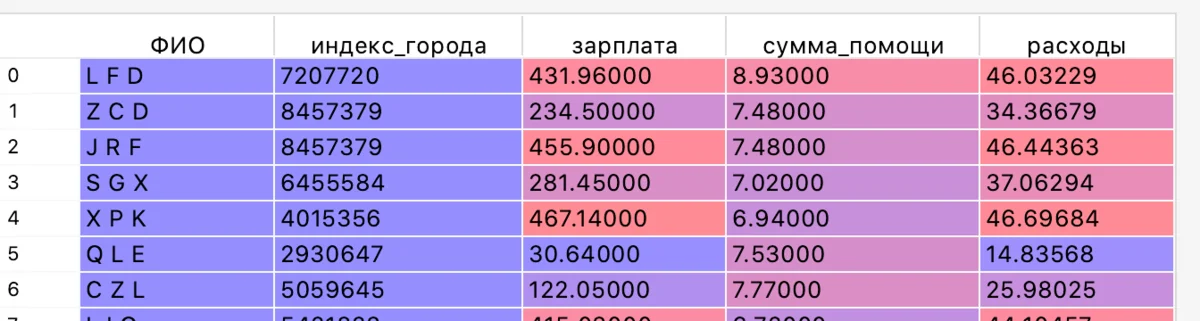
Также будем использовать обученную на этих данных модель градиентного бустинга CatBoost, построенную в этом примере.
Основная идея метода заключается в исследовании результатов работы модели при последовательном изменении каждого из параметров объекта в рамках некоторого диапазона. Это поможет локализовать набор факторов, оказывающих реальное влияние на конкретный прогноз.
Предполагается, что в нашем распоряжении имеется матрица с прогнозами, где находятся признаки интересуемого объекта перед предсказанием. На первом шаге загрузим матрицу признаков (df_pred) и выберем нужную строку (etal_str, пусть нулевая).
Далее зададим словарь с диапазонами значений параметров объекта (inds_values_d), указав в качестве ключа - индекс фактора и значения - список. Также предусмотрим возможность задания в качестве ключей имен столбцов (names_values_d), но в этом случае они будут преобразовываться в индексы и только в таком виде поступать в последующую обработку.
В блокноте эти шаги выглядят следующим образом:
Далее на базе интересуемой строки сформируем дополнительные с одним модифицируемым значением и склеим их в датафрейм:
Осталось загрузить модель и получить таблицу с предсказаниями:
Как можно заметить, ввиду особенности наших данных диапазон зарплат до 21 не влияет на прогноз (в обучающей выборке такие люди отсутствовали, и модель никаких выводов не сделала).
Теперь объединим сделанное в функцию, которая будет получать строку с признаками объекта, словарь модицикаций, модель, имя выходного файла и список признаков (последние два поля необязательные):
А так она применяется (отображен не весь вывод):