
Временной ряд – совокупность Наблюдений (Observation), собранных за определенный временной интервал. Этот тип данных используется для поиска долгосрочного тренда, прогнозирования будущего и прочих видов анализа. В отличие от Датасетов (Dataset) без временных рядов в качестве Признаков (Feature), наборы с временными рядами не выполняют основное требование линейной регрессии о независимости наблюдений.
Наряду с тенденцией увеличиваться или уменьшаться, большинство датасетов с временными рядами демонстрируют периодические (например, сезонные) тенденции. Например, изучая сбыт пуховиков на протяжении пяти лет, мы увидим более высокий их уровень продаж в холодное время года каждый год.
Такие свойства временного ряда коренным образом меняют характер работы при создании Модели (Model) Машинного обучения (ML). Прежде чем использовать такие данные для обучения Нейронной сети (Neural Network), стоит добиться так называемой Стационарности (Stationarity).
Стационарность
Стационарность – это свойство временного ряда, постоянство его статистических свойств: Cреднего значения (Average) и Дисперсии (Variance). Оно важно́, поскольку большинство моделей работают, исходя из предположения о стационарности: временной ряд ведет себя определенным образом, очень высока вероятность того, что он повторит те же паттерны в будущем. Стационарные ряды к тому же более просты в обработке.
Временные ряды и statsmodels
Поработаем с временным рядом – хронологией стоимости акции компании LG. Для начала протестируем данные на стационарность, то есть пригодность к использованию в качестве обучающих данных модели машинного обучения и предскажем стоимость бумаги с помощью Модели Бокса — Дженкинса (ARIMA). Для начала импортируем все необходимые библиотеки. Помимо классических библиотек NumPy и Pandas нам понадобятся также классы Среднеквадратической ошибки (Mean Squared Error), теста Дики-Фуллера (adfuller) и непосредственно модели ARIMA:
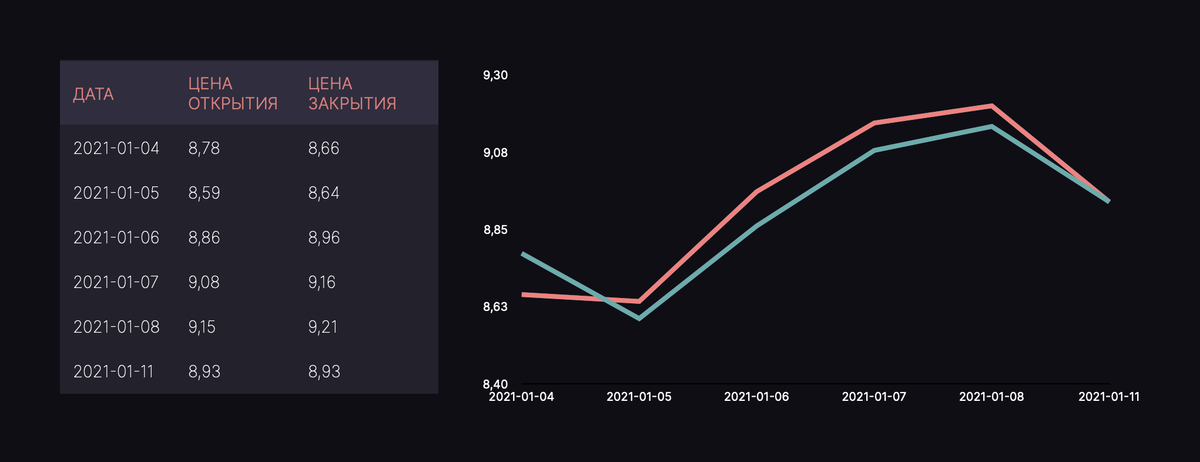
Теперь загрузим в ноутбук хронологию стоимости акции за текущий торговый год, то есть за период 01.01.2021 по 13.03.2021:
Мы получили такой игрушечный датасет с помощью сервиса Yahoo. Finance, и набор отображаемых признаков включает цены на момент открытия (OPEN [PRICE]), закрытия (CLOSE), максимальную (HIGH) и минимальную (LOW) цены дня, а также cкорректированную цену закрытия (ADJ CLOSE):
Отобразим с помощью Линейной диаграммы (Line Plot) цену акции на момент открытия биржи:
За два с небольшим месяца стоимость акции колебалась в пределах 8.5 – 11.5 долларов за штуку:
Именно с такими данными мы и будем создавать модель машинного обучения. Прежде чем приступить к построению модели, стоит выяснить, являются ли такие данные стационарными? В этом поможет тест Дики-Фуллера. Мы выберем Целевую переменную (Target Feature) , значение которой впоследствии и будем предсказывать, – это цена открытия (Open ) и сравним коэффициент такого теста с критическими значениями уровней Статистической значимости (Statistical Significance). Чтобы нейтрализовать восходящий тренд, мы логарифмизируем данные с помощью np.log , тем самым приведем более высокие поздние значения к масштабу более ранних:
Итак, метрика теста равна 0,220931, и само по себе это значение не очень показательно. Оно работает в сравнении с критическими значениями Статистической значимости. Итак, Статистика (Statistics) теста равна 0.220931, и это значение больше всех трех значениями уровней статистической значимости, что означает стационарность.
Настало время самой задорной части: предскажем стоимость акции. Для этого разделим датасет на Тренировочную (Train Data) и Тестовую части (Test Data) в пропорции 80 на 20. Для наглядности построим график, где эти части будут окрашены синим и красным соответственно:
Мы получили вот такое разделение:
Определим функцию smape_kun() , которая поможет в дальнейшем охарактеризовать эффективность предсказаний модели – Симметричная средняя абсолютная ошибка в процентах (SMAPE):
Создадим пустые списки predictions и history , которые будем пополнять предсказаниями, и запустим цикл длительностью в тестовую часть датасета:
Данных было немного, однако ошибка небольшая (измеряется в процентах):
Изучим сгенерированный список предсказаний, вызвав наполненный список predictions:
Мир неидеален, потому наш список наполнился предсказаниями – массивами в один элемент, что может сгененировать новичку дополнительную работу в будущем. Но, к счастью, не в нашем случае:
Для пущей наглядности визуализируем тестовые (реальные) значения стоимости акции и предсказанные:
Сейчас гораздо лучше видно, что модель не очень точна, вероятно, из-за малого объема тренировочных данных, но сейчас это не главное. Мы научились готовить данные с временными рядами к загрузке в модель.
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал . И попробуйте наши курсы по Машинному обучению на Udemy .