
Хоть тип char и относится к целочисленным типам данных (и, таким образом, следует всем их правилам), работа с char несколько отличается от работы с обычными целочисленными типами.
Тип данных char
Переменная типа char занимает 1 байт. Однако вместо конвертации значения типа char в целое число, оно интерпретируется как ASCII-символ.
ASCII (сокр. от «A merican S tandard C ode for I nformation I nterchange») — это американский стандартный код для обмена информацией, который определяет способ представления символов английского языка (+ несколько других) в виде чисел от 0 до 127. Например: код буквы 'а' — 97, код буквы 'b' — 98. Символы всегда помещаются в одинарные кавычки.
Таблица ASCII-символов :
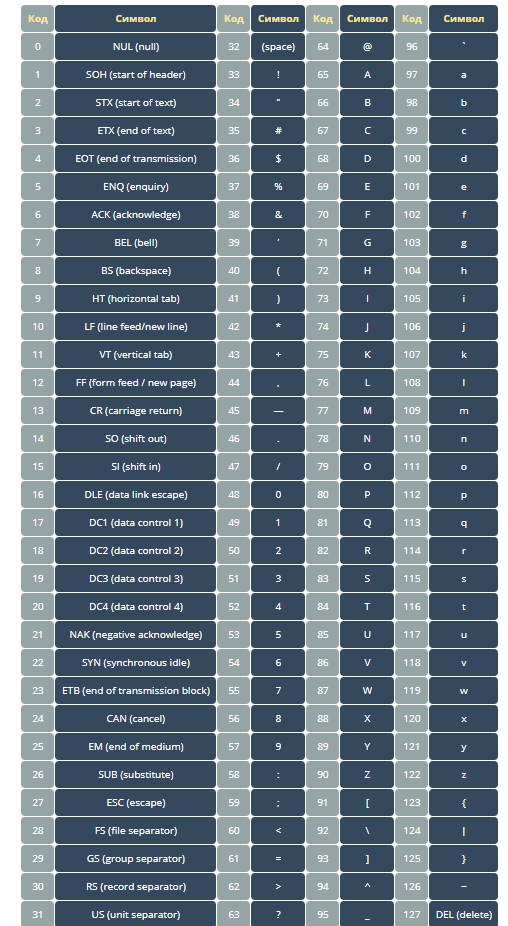
Символы от 0 до 31 в основном используются для форматирования вывода. Большинство из них уже устарели.
Символы от 32 до 127 используются для вывода. Это буквы, цифры, знаки препинания, которые большинство компьютеров использует для отображения текста (на английском языке).
Следующие два стейтмента выполняют одно и то же (присваивают переменным типа char целое число 97 ):
Будьте внимательны при использовании фактических чисел с числами, которые используются для представления символов (из ASCII-таблицы). Следующие два стейтмента выполняют не одно и то же:
Вывод символов
При выводе переменных типа char, объект cout выводит символы вместо цифр:
Результат:
a
Также вы можете выводить литералы типа char напрямую:
Результат:
b
Оператор static_cast
Если вы хотите вывести символы в виде цифр, а не в виде букв, то вам нужно сообщить cout выводить переменные типа char в виде целочисленных значений. Не очень хороший способ это сделать — присвоить переменной типа int переменную типа char и вывести её:
Результат:
97
Лучшим способом является конвертация переменной из одного типа данных в другой с помощью оператора static_cast .
Синтаксис static_cast выглядит следующим образом:
static_cast<новый_тип_данных>(выражение)
Оператор static_cast принимает значение из (выражения) в качестве входных данных и конвертирует его в указанный вами <новый_тип_данных> .
Пример использования оператора static_cast для конвертации типа char в тип int:
Результат выполнения программы:
a
97
a
Запомните, static_cast принимает (выражение) в качестве входных данных. Если мы используем переменную в (выражении) , то эта переменная изменяет свой тип только в стейтменте с оператором static_cast. Процесс конвертации никак не влияет на исходную переменную с её значением! В вышеприведенном примере, переменная ch остается переменной типа char с прежним значением, чему является подтверждением последний стейтмент с cout.
Также в static_cast нет никакой проверки по диапазону, так что если вы попытаетесь использовать числа, которые будут слишком большие или слишком маленькие для конвертируемого типа, то произойдет переполнение .
Более подробно о static_cast мы еще поговорим на соответствующем уроке.
Ввод символов
Следующая программа просит пользователя ввести символ. Затем она выводит этот символ и его ASCII-код:
Результат выполнения программы:
Input a keyboard character: q
q has ASCII code 113
Обратите внимание, даже если cin позволит вам ввести несколько символов, переменная ch будет хранить только первый символ (именно он и помещается в переменную). Остальная часть пользовательского ввода останется во входном буфере, который использует cin, и будет доступна для использования последующим вызовам cin.
Рассмотрим это всё на практике:
Результат выполнения программы:
Input a keyboard character: abcd
a has ASCII code 97
b has ASCII code 98
Размер, диапазон и знак типа сhar
В языке С++ для переменных типа char всегда выделяется 1 байт. По умолчанию, char может быть как signed, так и unsigned (хотя обычно signed). Если вы используете char для хранения ASCII-символов, то вам не нужно указывать знак переменной (поскольку signed и unsigned могут содержать значения от 0 до 127).
Но если вы используете тип char для хранения небольших целых чисел, то тогда следует уточнить знак. Переменная типа char signed может хранить числа от -128 до 127. Переменная типа char unsigned имеет диапазон от 0 до 255.
Управляющие символы
В языке C++ есть управляющие символы (или «escape-последовательности» ). Они начинаются с бэкслеша (\ ), а затем следует определенная буква или цифра.
Наиболее распространенным управляющим символов в языке С++ является '\n' , который обозначает символ новой строки:
Результат:
First line
Second line
Еще одним часто используемым управляющим символом является \t , который заменяет клавишу TAB, вставляя большой отступ:
Результат:
First part Second part
Таблица всех управляющих символов в языке C++ :
Рассмотрим пример в коде:
Результат выполнения программы:
"This is quoted text"
This string contains a single backslash \
6F in hex is char 'o'
Что использовать: ‘\n’ или std::endl?
Вы могли заметить, что в последнем примере мы использовали '\n' для перемещения курсора на следующую строку. Но мы могли бы использовать и std::endl . Какая между ними разница? Сейчас разберемся.
При использовании std::cout, данные для вывода могут помещаться в буфер, т.е. std::cout может не отправлять данные сразу же на вывод. Вместо этого он может оставить их при себе на некоторое время (в целях улучшения производительности).
И '\n' , и std::endl оба переводят курсор на следующую строку. Только std::endl еще гарантирует, что все данные из буфера будут выведены, перед тем, как продолжить.
Так когда же использовать '\n' , а когда std::endl ?
Используйте std::endl , когда нужно, чтобы ваши данные выводились сразу же (например, при записи в файл или при обновлении индикатора состояния какого-либо процесса). Обратите внимание, это может повлечь за собой незначительное снижение производительности, особенно если запись на устройство происходит медленно (например, запись файла на диск).
Используйте '\n' во всех остальных случаях.
Другие символьные типы: wchar_t, char16_t и char32_t
Тип wchar_t следует избегать практически во всех случаях (кроме тех, когда происходит взаимодействие с Windows API).
Так же, как и стандарт ASCII использует целые числа для представления символов английского языка, так и другие кодировки используют целые числа для представления символов других языков. Наиболее известный стандарт (после ASCII) — Unicode , который имеет в запасе более 110 000 целых чисел для представления символов из разных языков.
Существуют следующие кодировки Unicode :
- UTF-32 — требует 32 бита для представления символа.
- UTF-16 — требует 16 бит для представления символа.
- UTF-8 — требует 8 бит для представления символа.
Типы char16_t и char32_t были добавлены в C++11 для поддержки 16-битных и 32-битных символов Unicode (8-битные символы и так поддерживаются типом char).
В чём разница между одинарными и двойными кавычками при использовании с символами?
Как вы уже знаете, символы всегда помещаются в одинарные кавычки (например, 'а' , '+' , '5' ). Переменная типа char представляет только один символ (например, буква а , символ + , число 5 ). Следующий стейтмент не является корректным:
Текст, который находится в двойных кавычках, называется строкой (например, "Hello, world!" ). Строка (тип string ) — это набор последовательных символов.
Вы можете использовать литералы типа string в коде:
Более подробно о типе string мы поговорим на соответствующем уроке.