Классная практическая статья Working with large CSV files in Python from Scratch рассказывает о хитростях работы с большими CSV-файлами.
В статье рассматриваются примеры:
— подсчёт строк в большом файле. Для этого применяется mmap, который использует низкоуровневое API операционной системы. Это позволяет ускорить чтение большого файла. Сам mmap заслуживает отдельной статьи. В ней с примерами на питоне объясняется, откуда берётся ускорение, плюс другие интересности, в том числе уровня системных вызовов ядра
— разбиение большого файла на части, с которыми дальше удобнее работать
— перемешивание строк в файле. Такое бывает нужно, когда данные используются для обучения модельки машинного обучения
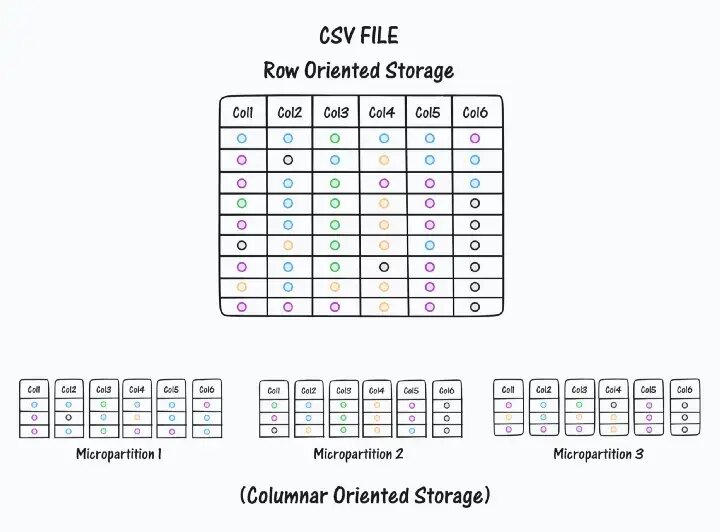
— хранение в виде столбцов ускорит выполнение запросов путём ограничения данных, среди которых идет поиск. Этот пункт достаточно хардкорный, рекомендуем пройтись отладчиком по коду — иначе не разобраться в нюансах
Мы на практике неоднократно сталкивались с гигабайтными CSV, которые иногда даже не умещались в оперативную память.
Например, вы знаете, что линуксовый sort --unique читает файл целиком в оперативную память? А для работы ему надо примерно в 2,5 раза больше памяти, чем весит исходный файл. То есть для сортировки файла в 10 гигов нужно около 25 гигов оперативной памяти. Решение этой проблемы заслуживает отдельного поста.