Видео с уроком:
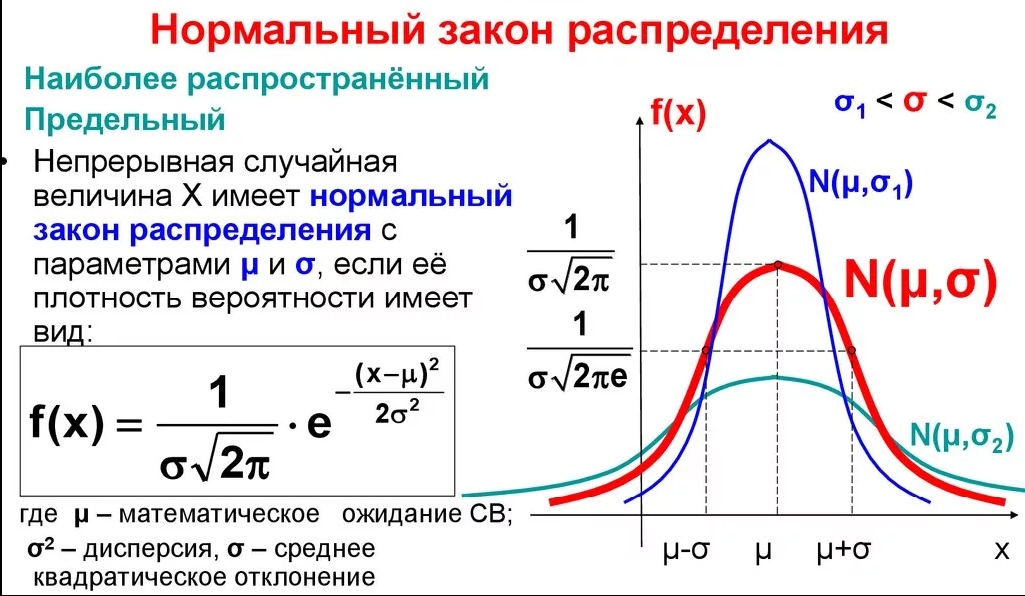
Генерируем с помощью надстройки «анализа данных» -«генерация случайных чисел» нормально распределённую случайную величину мат.ожиданием равным 0 и стандартным отклонением 1.
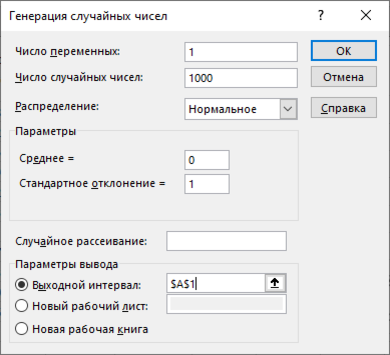
В ячейках А1-А1000 получаем значения случайной величины, подчинённой нормальному закону распределения с параметрами: мат.ожиданием = 0 и стандартным отклонением =1.
Построим на основании полученных данных дискретный вариационный ряд.
С помощью функции МИН находим минимальное значение из полученных данных: D1 =МИН(A1:A1000).
С помощью функции МАКС находим максимальное значение из полученных данных: D2 =МАКС(A1:A1000).
Находим размах вариации (R= Хмакс – Хмин): D3 =D2-D1.
Число интервалов определяем по формуле Стерджесса:
D4 =1+3,322*LOG(1000).
Определяем величину интервала: l=R/n
Определяем границы интервалов.
Первый нижний интервал равен минимальному значению ряда (G2 =D1). Первый верхний интервал равен значение нижнего плюс величина интервала (H2= =D1+D5). И так далее.
Последний верхний интервал равен максимальному значению ряда.
С помощью функции ЧАСТОТА находим число попаданий случайной величины в полученные интервалы вариационного ряда.
Что бы заполнились все клетки частот необходимо одновременно нажать:
Получим частоты ряда распределения.
Видим, что сумма частот не равна 1000. Не хватает одного наблюдения. Это произошло из за того, что верхний интервал ряда не считается, и последний верхний интервал не был посчитан. Что бы его учесть прибавляем малое число к верхней границе последнего интервала.
H12 =H11+D$5+0,000001
Теперь сумма частот равна 1000.
Находим среднее значение массива данных с помощью функции СРЗНАЧ:
G16 =СРЗНАЧ(A1:A1000)
Стандартное отклонение массива данных находим с помощью функции СТАНДОТКЛОН.В:
G17 =СТАНДОТКЛОН.В(A1:A1000)
Найдём среднее и стандартное отклонение построенного интервального вариационного ряда. Находим середину интервала:
j2 =(G2+H2)/2
аналогично для других интервалов.
Находим произведение середины интервала на частоту:
K2 =J2*I2
аналогично для других интервалов.
Находим произведение квадрата середины интервала на частоту:
L2 = =J2^2*I2
аналогично для других интервалов.
Далее суммируем полученные столбцы и получаем таблицу.
Среднее значение определяем по формуле:
H16= =K13/I13
Стандартное отклонение определяем по формуле:
Полученные значения среднего и стандартного отклонения по массиву данных и по интервальному ряду имеют небольшое расхождение. Так и должно быть, так как методики определения различны.
Далее нами была построена гистограмма интервального ряда распределения.
P.S.
На следующем занятии мы проверим, подчиняется ли полученный интервальный ряд нормальному распределению, будем использовать функции НОРМРАСП и ХИ2.ОБР https://dzen.ru/a/Y4cyLlERd0hh00_s
С нами учёба станет легче 🤓 Здесь консультируют, учат, проводят курсы и просто выручают студентов всех вузов! Работаю со студентами с 1999 года, имею большой опыт консультирования.
Онлайн-консультирование по экономическим и математическим предметам. Математика, математические методы и модели, статистика, эконометрика, макроэкономика, анализ хозяйственной деятельности, экономический анализ, финансовый менеджмент, финансовая математика, международные стандарты финансовой отчётности, и другие предметы.
Консультации в расчётах исследовательских и студенческих работ программах Excel, Eviews, Gretl, Statistica, SPSS, R-studio.Так же обучаем работе с данными программами. Помощь в сдаче экзаменов. По всем вопросам пишите в telegram (https://t.me/sm_smysl ) или в форму сбора заявок на сайте.
Онлайн помощь студентам: https://pro-smysl.ru/
Подписывайтесь на наши каналы:
https://www.youtube.com/@SMYS_L