
Зачастую при отсутствии структурированных данных и возможности их сбора посредством интерфейсов прикладного программирования (API) аналитик вынужден проводить парсинг веб-страниц, возвращаемых в сыром виде (веб-скрапинг). Незаменимым инструментом для этого являются библиотеки requests, urllib (для получения контента), beautifulsoup4 (для разбора контента). Представляю один из вариантов функции, получающей содержимое страницы:
import requests
import random
import time
def get_url_delay(delay,url):
session = requests.Session()
user_agent_list = [
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)'
]
referer_list=['https://www.yandex.ru/','https://yahoo.com/','https://www.msn.com/','https://www.tut.by/','http://www.br.by/','http://www.zubr.com/','http://www.tit.by/']
referer= random.choice(referer_list)
user_agent = random.choice(user_agent_list)
# Set the headers
headers = {'User-Agent': user_agent, "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8", 'Accept-Language': 'ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7','Referer':referer}
req = session.get(url, headers=headers)
time.sleep(delay)
return req
В данной функции перед отправкой запроса отдельные поля заголовков ('User-Agent' и 'Referer') заполняются случайными значениями (функция random.choice()) для имитации работы с различных систем, а также намеренно вводится временная задержка, чтобы не обрушить сервер большим потоком запросов. В последующем с возвращаемым значением можно работать посредством библиотеки beautifulsoup4.
Самыми часто используемыми методами объекта BeautifulSoup являются find и findAll, позволяющие получать первый и все результаты поиска тегов и их атрибутов. Для этого лучше всего использовать следующий синтаксис вызова - find(имя_тега, {имя_атрибута1:значение1,…}). Также распространен вызов find(text=значение), получающий тег с заданным текстом внутри. У метода findAll синтаксис с данными аргументами аналогичен. Для навигации по тегам могут пригодиться свойства parent и children.
После получения тегов может потребоваться вернуть их содержимое либо атрибуты. Для этого предназначены метод get_text(), удаляющий все теги из объекта и возвращающий только блоки текста, а также свойство attrs, возвращающее словарь со списком атрибутов и их значений.
Перейдем к практике и произведем частичный разбор полей стартовой страницы сайта ufcstats.com. Например, получим ссылки на проведенные мероприятия. Для этого перейдем по данному адресу в браузере, наведем курсор на элемент списка, нажмем правой кнопкой мыши и выберем исследовать элемент.
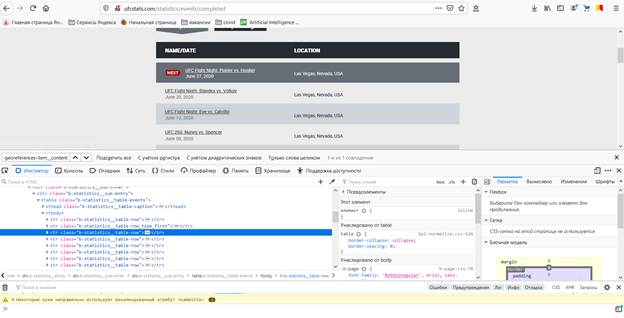
Как можно убедиться, интересуемое нас содержимое располагается в тегах «tr», значением атрибута «class» которых является строка «b-statistics__table-row». Получим их:
html = get_url_delay(1,'http://ufcstats.com/statistics/events/completed').text
bsObj = BeautifulSoup(html)
fights = bsObj.findAll('tr',{'class':'b-statistics__table-row'})
Если раскрыть строчку таблицы, то увидим, что она состоит из двух ячеек, при этом ссылки содержатся в первой (ориентироваться целесообразно на цвет элементов страницы, так как активное содержимое выделяется при наведении курсора на соответствующий ему исходный код):
Дальнейшее продвижение по списку приведет нас к дочерним тегам, содержащим интересуемую информацию. Потому немного перепишем первоначальный код и добавим выборку ссылок.
html = get_url_delay(1,'http://ufcstats.com/statistics/events/completed').text
bsObj = BeautifulSoup(html)
hrefs = bsObj.findAll('a',{'class':'b-link b-link_style_black'})
hrefs = [item.attrs['href'] for item in hrefs]
Итоговый список ссылок получается извлечением значений атрибута «href» для каждого тэга, полученного на предыдущем шаге.