Видео в конце...
В этой статье мы рассмотрим наиболее модное направление в области разработки аппаратных платформ. Это, так называемый, синтез высокого уровня или HLS. Предпосылки изменений в области разработки аппаратных платформ заключаются в том, что в проектировании процессоров общего назначения наметился кризис. Каждое улучшение технологического процесса требует огромных вложений в строительство высокотехнологичных линий производства. Цены на топовые процессоры взлетели вверх. Потребителям все сложнее оплачивать такой прогресс. А поскольку деньги приходят все сложнее и сложнее, то и прогресс существенно замедлился. Крупнейший производитель процессоров Intel приобрел одного из крупнейших разработчиков ПЛИС и исследования пошли в сторону параллелизации вычислений. Вот примерно так можно описать предысторию ближайшей революции в области вычислений.
Особенности новой технологии
Перейдем к сравнению технологий разработки проектов. Еще в 80-х годах прошлого столетия в области разработки цифровых устройств начали применяться специализированные языки проектирования, называемые еще языками описания аппаратуры или HDL языки. Наиболее широкое распространение получили VHDL и Verilog. Эти замечательные языки позволяют вести разработку цифровых схем как на самом низком уровне, работая с отдельными вентилями, и иногда даже с транзисторами, таки на самом высоком структурном уровне.
Одновременно возможности низкого и высокого уровня разработки это не только удобное разбиение одной большой задачи на небольшие, это понятная любому инженеру иерархия и высокая синтаксическая эффективность языков. Они дают разработчикам широчайшие возможности. Эти языки изначально создавались для решения конкретных задач и поэтому в них были заложены вполне определенные синтаксические инструменты. Сложно представить языки более пригодные для разработки с использованием ПЛИС.
Такое полезное свойство интегральных схем, как высокая производительность постепенно выходит на самый первый план. Остается решить одну маленькую проблему. Называется она довольно просто. Это острая нехватка квалифицированных специалистов, способных перенести большое количество уже разработанных алгоритмов с традиционных языков программирования на язык описания аппаратуры. В идеальных представлениях фундаментальные алгоритмы, описанные на языках Си и С++, являющиеся сердцем высоконагруженных приложений должны быть без особых доработок преобразованы в максимально быстродействующие схемы, способные быстро, желательно за один такт получать нужный результат вычислений. Такие схемы должны быть очень эффективно разложены на ресурсы ПЛИС. В этом идеально нарисованном мире многие сервисы мировой паутины смогут существенно увеличить производительность и при этом сократить количество технических средств в серверных стойках, снизить энергопотребление и уменьшить вредные выбросы электростанций в атмосферу.
Краткий обзор технологии HLS
Идеальный мир он таков. Но как дела обстоят сейчас? Можно ли напрямую перенести алгоритмы на ПЛИС? Что этому мешает и какова реально занимаемая новой технологией ниша?
В настоящий момент Intel и Xilinx как два задающих моду производителя рассматривают языки Си и С++ в качестве инструмента переноса алгоритмов в новый мир параллельных вычислений. Это обосновано тем, что за более чем 45 лет существования языка Си, на нем написаны практически все известные алгоритмы и конечно же все самые важные и фундаментальные из них.
В ранних публикациях совсем не зря упор делался на технические подробности. В простом процессоре для вычислений выделяется одно арифметико-логическое устройство. Так вот, чтобы прийти к конечному решению, мы настроили свое сознание так чтобы разложить все вычисления на конечное число простых операций. Выполняя их в строго определенном порядке, процессор придет к решению задачи. Это все именуют алгоритмом.
Правильный порядок выполнения операций процессором достигается слаженной работой массы специальных модулей. Это флаги выполнения операций, дешифратор команд, управляющий направлением данных к тому или иному узлу процессора. Выполнение функции сопровождается передачей параметров через стек, сохранением адреса возврата, размещением в стеке локальных переменных. Это все приводит ко многим машинным инструкциям, на которые уходят бесчисленные такты процессора и соответственно большое количество времени.
Теперь же в новой параллельной вселенной все будет совсем не так. Больше нет такой вольности, как бесчисленное количество тактов.
Время теперь это наиболее ценный ресурс.
Чтобы обеспечить максимально параллельное и быстрое выполнение вычислений, в нашем распоряжении большое число ресурсов ПЛИС, буквально утопающих в матрице коммутации. И с этим всем хозяйством необходимо обращаться крайне разумно и осторожно. Давайте на простых примерах посмотрим сколько новой информации необходимо иметь ввиду простому программисту, чтобы используя традиционный язык программирования очень коротко и точно выразить свою мысль системе проектирования.
Кто есть кто теперь?
Итак, функции это теперь не размещение аргументов и переменных в стеке. Стека теперь вообще не существует. Функция это самостоятельный блок, на вход которого приходят аргументы.
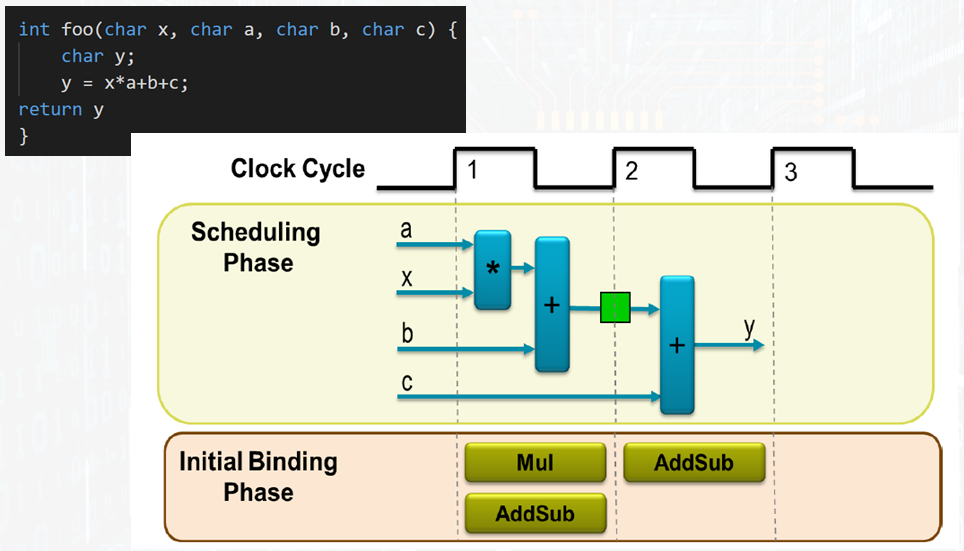
В этом примере на входе 4 шины данных. На выходной шине данных появится результат. Для выполнения всех операций достаточно одного умножителя и одного сумматора. Если иметь два сумматора, то функция выполнится максимально быстро, но при этом будет задействовано максимальное количество ресурсов. Компромиссный вариант потребует одного сумматора и результат выполнения функции появится на втором такте.
Один и тот же сумматор на первом такте сработает в операции суммы произведения с числом b, результат будет записан в регистр, изображенный зеленым цветом. На втором такте произойдет сумма промежуточного результата, с числом c. На вход сумматора будут поданы совсем другие слагаемые. Это довольно легко решается при помощи мультиплексора.
Даже на таком простом примере видно, что можно довольно гибко управлять производительностью вычислительного процесса и подбирать компромиссные решения. Обычный программист, приходящий в эту область должен хорошо представлять все возможные варианты и какими средствами ими можно управлять.
Теперь пример немного сложнее.
На входе функции имеются массивы чисел, один входной и один выходной. Кроме того, в теле функции присутствует цикл. Если подходить к решению задачи с позиции экономии ресурсов, распараллеливается тело цикла, но каждая итерация приводит к повторному использованию все тех же сумматоров и умножителей. Итеративное выполнение обеспечивает такой механизм, как автомат состояний. Это далеко не всем понятный термин и для полного понимания прийдется посвятить ему отдельную статью.
Теперь необходимо отметить, что массивы данных передаются от функции к функции через блоки памяти.
Это один из основных ресурсов ПЛИС, позволяющий вести одновременную запись и чтение. Этому способствует наличие двух независимых комплектов шин и управляющих линий блочной памяти. За один такт можно считать или записать только одну ячейку данных. Доступ к ячейкам осуществляется отдельным механизмом вычисления адреса, работа которого контролируется при помощи все того же автомата состояний.
На рисунке ниже общее количество тактов, необходимое схеме для достижения результата.
Такое количество определяет задержку получения результата и такой термин, как латентность. Среди этих действий есть как чтение элементов массива из памяти, так и запись результата в выходной массив, расположенный в другом модуле памяти. Если обычный процессор для достижения результата должен будет выполнить массу операций, то такая довольно простая схема справится за 10 тактов. Это уже не так много, но если требуется исключительная производительность, то можно пожертвовать чуть большим количеством ресурсов.
Конвейерное вычисление
При обычном подходе к реализации тела цикла мы получаем долгое время ожидания результата. При применении конвейерного способа вычислений одна часть схемы занимается одной операцией и передает результат на вторую часть, где происходит вторая операция.
После второй операции результат подается далее. Независимая параллельная работа таких частей приводит к тому, что в один и тот же момент выполняется несколько независимых операций. Так, в этом примере происходит одновременно считывание последнего числа из входного массива, вычисление с использованием среднего числа из массива и запись результата вычисления после операции над самым первым числом из массива. Как можно заметить, латентность функции сократилась в два раза. Конечно, при этом неизбежно подрастает количество используемых ресурсов.
Использование директив синтеза
Одним из самых загадочных вопросов во всем этом является способ управления латентностью и количеством используемых в вычислениях ресурсов. Как можно понять, языки Си и С++ не имеют штатных лексических конструкций для использования в той области, где их никогда не ждали. Но по счастью существуют такое понятие как директивы и уж они и являются "заклинаниями", при помощи которых можно контролировать нужный уровень производительности.
В этом примере функция обрабатывает буфер данных, предназначенных для вывода на экран. При размере изображения 640 на 480 пикселей необходимо обработать более трехсот тысяч чисел, каждое из которых отвечает за цвет своего пикселя на экране. И если еще для обработки одного пикселя требуется многошаговый цикл, то очень даже целесообразно распараллелить выполнение тела небольшого цикла чтобы ускорить обработку буфера данных. Делается это при помощи директивы pragma HLS PIPELINE II=1. Таких директив всех разновидностей довольно большое количество и каждая для чего-то предназначена.
Российские разработки в области параллельных вычислений
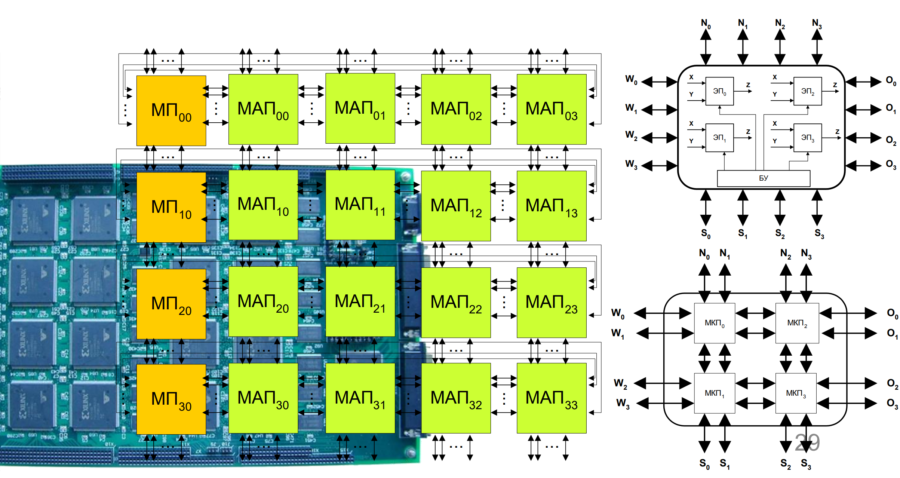
Как это обычно и бывает, шум вокруг этой темы поднялся только сейчас, но работы начались задолго до этих событий. Еще с 90-х годов появляются публикации на тему использования популярных языков программирования в области разработки проектов для ПЛИС. В России это направление проработано довольно обстоятельно и глубоко. Еще с начала 2000-х годов прорабатываются технологии использования матриц из ПЛИС, функционирующих как единый вычислитель. Созданы соответствующие средства разработки, позволяющие автоматизировать процесс разбиения всего большого проекта на отдельные части, логическая сложность которых позволяет поместить их в каждую отдельную интегральную схему.
Посмотреть там, действительно, есть на что. Эти инженеры формируют наше будущее. Вычислительные модули отечественного производства обладают рекордными показателями производительности на единицу занимаемого объема. Это стало возможным при использовании жидкостного охлаждения.
И это не просто шланги внутри системного блока, это модули, погружаемые целиком в жидкую среду, непрерывную циркуляцию которой обеспечивают насосы и трубопроводы. Только одна такая стойка вычислителей способна противостоять суперкомпьютеру RoadRunner фирмы IBM, состоящему из 18 стоек такого же размера.
Быть может еще через лет пять такие технологии станут доступными не только корпорациям, но и для широкого потребителя и тогда вероятнее многим из нас представится возможность пробовать свои силы в этой области. А пока необходимо к этому подготовиться и освоить основные термины, определения, разобраться во всех тех новых способах организации вычислений, которые используются в новых технологиях. Вот для всего этого и будут предназначены дальнейшие публикации.
Поддержите статью лайком если понравилось и подпишитесь чтобы ничего не пропускать.