Подсистема памяти современных процессоров давно и прочно перекочевала из набора системной логики в сами ЦП, будь то монолитный кристалл или мультикристальная сборка, как у новых AMD Rome. Однако у такого подхода есть не только плюсы. Количество каналов доступа к памяти выросло до 8 и уже рассматриваются проекты с 10 каналами.
Но при таком подходе увеличение числа каналов делает процессоры более сложными и громоздкими: только подсистема памяти может потребовать порядка 300 контактов, которые ещё надо развести и подключить к и без того огромному у современных многоядерных CPU набору «кремния». А ведь ещё и на PCIe приходится выделять контакты. Усложняется и конструкция системных плат, особенно при попытке увеличить количество слотов DIMM и PCIe.
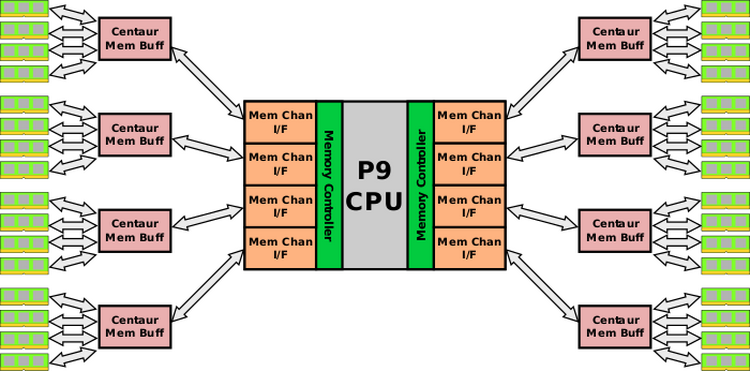
Компания IBM предлагает полностью переосмыслить подход к организации подсистем памяти в высокопроизводительных решениях с помощью нового последовательного стандарта Open Memory Interface (OMI). Нельзя сказать, что сама идея нова: попытки внедрить последовательную шину памяти вместо параллельной предпринимались и ранее, достаточно вспомнить стандарт FB-DIMM, который погубило высокое энергопотребление и тепловыделение чипа буферизации на каждом из модулей памяти. Похожую схему использует в настоящее время использует IBM в процессорах серий POWER8 и POWER9 Scale-Up.
Контроллер памяти у этих чипов устроен иным образом, нежели в привычных Intel Xeon или AMD EPYC. В нём нет части, отвечающий за физический уровень (PHY) — непосредственно с модулями DIMM имеет дело специальный чип-буфер Centaur, который посредством одноимённого последовательного интерфейса со скоростью 9,6 гигатранзакций в секунду (28,8 Гбайт/с) уже связывается с процессором.
Таких интерфейсов в современных процессорах IBM восемь, что даёт совокупную производительность на уровне 230 Гбайт/с. Это позволяет сэкономить площадь кристалла, которая у процессоров POWER и так очень велика ‒ свыше 700 мм2, а значит, и снизить себестоимость конечных изделий. Из-за Centaur задержка обращений к памяти увеличивается в среднем на 10 нс, что не так уж много. К тому же частично она «сглаживается» L4-кешем.
Новая разработка корпорации базируется на идеях, уже реализованных в Centaur, но, в отличие от последнего, является полностью открытой. В основе интерфейса OMI лежат семантика и протоколы доступа к памяти, описанные в стандарте OpenCAPI 3.1. А опирается OMI на шину BlueLink (25 Гбит/с), которая в нынешних POWER-чипах отвечает за работу NVLink и Open(CAPI). Всё это очень напоминает инициативу CXL.
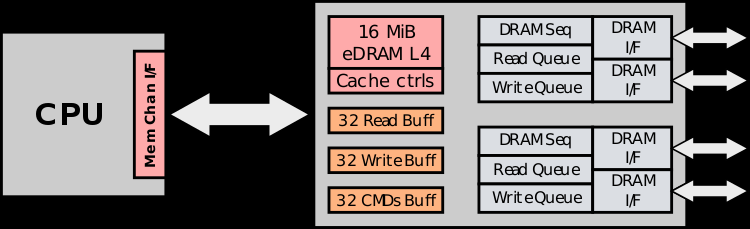
Реализация OMI существенно проще Centaur, она позволяет сделать чип-буфер более компактным и менее горячим. Это, в свою очередь, упрощает компоновку и площадь процессорного кристалла, ведь при последовательном доступе общее количество контактов, отвечающих за память, можно снизить с ~300 до 75. В данной схеме ЦП посылает только простые команды загрузки и сохранения, вся реализация физического интерфейса лежит на плечах чипа-компаньона OMI. В нём же может находиться дополнительный кеш.
Помимо экономии контактов такой подход позволяет использовать практически любой тип памяти, будь то DDR, GDDR или NVDIMM. Пока что основная цель — поддержка DDR5. Интерфейс OMI унифицирован и слоты нового типа автоматически совместимы с любыми модулями, отвечающими стандарту.
При использовании микросхем DDR4 система с интерфейсом OMI может иметь совокупную производительность до 650 Гбайт/с. Для RDIMM увеличение задержки составляет 5–10 нс, а для LRDIMM и вовсе около 4 нс. На подобные скорости способны только сборки HBM, которые в силу своей природы имеют весьма ограниченную ёмкость и очень дороги в реализации.
Располагаться чип-буфер OMI может как на системной плате, так и на модуле памяти; последний вариант является основой нового стандарта. Он предусматривает 84 контакта на модуль, сами модули получили название Dual-Inline Memory Module (DDIMM).
Они компактнее традиционных DDR4 RDIMM: ширина модуля сократилась со 133 до 85 мм. Реализация буфера OMI ↔ DDR4 уже существует в кремнии: компания Microsemi продемонстрировала свою реализацию в лице чипа SMC 1000 (PM8596), поддерживающего 8 линий OMI со скоростью 25 Гбит/с каждая. Допустима также работа в режиме 4×1 с вдвое меньшей общей пропускной способностью.
С «другой стороны» SMC 1000 реализован стандартный 72-битный интерфейс и поддерживаются различные комбинации DDR4 и флеш-памяти. Тактовая частота DRAM-микросхем может составлять до 3200 МГц. Высота модуля OMI DDIMM зависит от типа и комбинации устанавливаемых чипов — у NVDIMM она будет больше, нежели в случае использования только DDR4.
При одиночной высоте максимальная ёмкость составляет 128 Гбайт, двойная позволяет в перспективе создавать модули памяти объёмом более 256 Гбайт. Сам буфер SMC 1000 компактен, его размеры составляют всего 17×17. Низкое тепловыделение гарантирует отсутствие проблем, свойственных FB-DIMM.
Что касается процессоров с поддержкой OMI, то первым решением такого типа стал новый вариант IBM POWER9 Advanced I/O (AIO). Отличие от версий Scale Up (SC) и Scale Out (SO) отмечено в самом названии. Новые чипы получили не только поддержку новой шины памяти OMI (16 каналов по 8 линий = 650 Гбайт/с), но и новые версии интерфейсов NVLink (возможно, 3.0) и OpenCAPI 4.0. Имеется также 48 линий PCI Express 4.0.
За счёт шины PowerAXON (новое имя для BlueLink) возможна реализация 16-сокетных систем без применения дополнительной логики. Фактически в новых процессорах остаётся только два вида основных внешних шин: BlueLink для AXON и OMI + PCI-E 4.0. Количество ядер в POWER9 AIO может достигать 24, что с учётом поддержки SMT4 даёт 96 исполняемых потоков. Дополнительно в корпусе POWER9 AIO имеется 120 Мбайт кеша L3 типа eDRAM. Техпроцесс остался прежним — 14-нм FinFET.
Поставки новых процессоров IBM POWER9 с расширенными интерфейсными возможностями должны начаться в следующем году. Стоимость неизвестна, но с учетом 8 миллиардов транзисторов и площади кристалла 728 мм2 она будет достаточно высокой; впрочем, как уже говорилось, за счет внедрения OMI кристалл удалось существенно упростить.
В комплект поставки IBM включила и чип-буфер OMI ↔ DDR4, его пиковая производительность составляет 410 Гбайт/с, что заметно ниже возможностей самого процессора. Следовательно, имеется место для роста и будущей модернизации систем на базе POWER9 AIO, причём сама модернизация будет заключаться только в замене модулей памяти на более производительные.
Следующее поколение, POWER10, ожидается только в 2021 году. К этому времени стандарт OMI DDIMM должен стать основным для производительных многопроцессорных систем. Кроме того, IBM попутно готовит и новые версии OpenCAPI, которые не будут привязаны к архитектуре POWER, что откроет дорогу к OMI другим вендорам. А увеличение скорости одной линии до 32 или 50 Гбит/с позволит составить конкуренцию PCI-E 5.0. Впрочем, POWER10 получит поддержку и этой шины.