
Сегодня мой друг Стефан, который занимался разработкой компиляторов в университете (у меня такого курса не было), сказал такую вещь: "Шаблоны в С++ по своей выразительности срисованы с Пролога". И я прозрел. Я хорошо понимал Пролог в институте, но связать с шаблонами не мог. Оказалось что они очень и очень похожи. И для того, чтобы показать это, мы сейчас напишем сортировку в compile-time.
Основной языка Пролог является механизм сопоставления с шаблоном (pattern matching), поэтому сортировка Хоара (быстрая) записывается следующим образом:
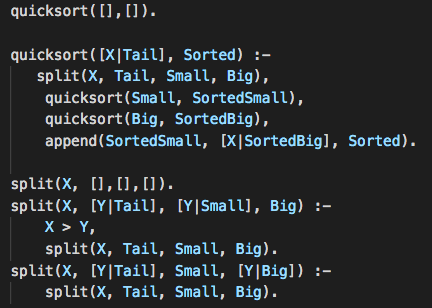
Что мы тут видим: результатом работы quicksort для пустого списка является пустой список. Результатом работы quicksort в другом случае является список Sorted, который получается путем приписывания (append) отсортированных чисел, меньших X, к отсортированному списку, состоящему из X и чисел, больших чем X.
Давайте попробуем сделать то же самое на C++. Нам еще потребуется немного Lisp-образных списков. Итак, самое базовое это список. Но наш список в C++, это не list. Это шаблонная структура, у которой есть два поля: поле данных value и typedef, "указывающий" на тип хвоста списка. В этой статье мы оперируем только типами.
Давайте не думать про слово template, а писать как будто на Питоне, Лиспе или Прологе. У структуры Node есть Head, где хранится некоторое значение и Tail, где тоже хранится некоторое значение. Тип Head это число, int, тип Tail это "тип данных". Да, все мета программирование строится на том, что можно иметь переменную типа "тип данных".
Как мы можем создать список?
Инстанциирование шаблона (примерение <>) можно сказать что создает новую "переменную" типа "тип данных". Поэтому мы создаем Node<0, Terminate> - это наша такая новая переменная. которая, собственно, содержит 0 в поле Head и тип Terminate в поле Tail. И затем создаем еще одну переменную Node<3, ...>, которая в качестве второго аргумента принимает первую. Самое главное не начать думать об этом как о каких-то там классах и типах. Сейчас для нас все эти классы и типы это просто какие-то переменные.
Отлично, у нас есть списки. Надо что-то с ними делать! Самое простое это добавить элемент в начало:
Для того чтобы добавить элемент N к списку L, мы создаем переменную Head, в которую кладем переменную типа Node, со значением головы N и с хвостом L.
Дальше чуть по-сложнее: слияние списков. Если есть два списка вида [Голова1 | Хвост1] и [Голова2 | Хвост2], то
- Слияние([Голова1 | Хвост1], [Голова2 | Хвост2]) = Node(Голова1, Слияние(Хвост1, [Голова2 | Хвост2]))
- Слияние([], Какой-то-Список) = Какой-то-Список.
Уже неплохо, можно протестировать:
Дальше, вероятно, самая запутаная часть кода. По-хорошему нам нужна структура Filter, которая
- если голова списка соответствует какому-то критерию, оставляет её, а в качестве хвоста устанавливает результат работы Filter для хвоста
- иначе результат работы Filter это результат работы Filter для хвоста
- результат работы Filter для пустого списка Terminate это пустой список.
Однако, нам будет нужно создать несколько фильтров с разными критериями. Получится так, что для каждого из критериев, надо будет писать 3 структурных шаблона. Поэтому я решил вынести часть кода за скобки. Получилось, сразу скажу, не очень. И наверняка можно было улучшить, но пока оставлю как есть.
FilterImpl принимает 3 параметра: bool — значение предиката для головы списка, сам предикат (обратите внимание - "указатель на функцию" в мире шаблонов называется шаблонным шаблонным параметром), и список. Далее следует 4 специализации: для разных значений предиката и для пустого / непустого списков. Как мы и говорили, если предикат истинен, мы создаем node со значением List::Head и хвостом равным результату применения предиката к хвосту и так далее.
Теперь собственно, предикаты которые нам нужны:
Предикат принимает на вход 2 значения — значения порога для фильтрации, int, и список. Создает внутри себя "замыкание" — для того чтобы сделать из себя "чистый" предикат, который принимает на вход только список. То есть, говоря простым русским языком, значение N получается забинженным.
Ну а "значение" (как можно было заметить, мы кладем все "значения" в "переменную" Head) это результат применения FilterImpl, куда в качестве значения передаются уже реальные bool значения, замыкание и список.
Сама сортировка после этого выглядит очень даже пристойно :)
Справитесь без комментариев?
Исходный код доступен здесь.