В данном материале я разберу пример работы с библиотекой PHP-ML (Machine Learning library for PHP). PHP-ML – это довольно удобная и активно-развивающаяся библиотека для прогнозирования, анализа данных и использования элементов искусственного интеллекта в своих проектах. Но библиотека еще находится на стадии разработки.
Суть моего примера заключается в том, чтобы основе известных характеристик домов (площадь, количество спален и т.д.) научить программу прогнозировать итоговую цену этих домов.
Для того чтобы это осуществить нам нужно подготовить специальную регрессионную модель. Для нее нужен готовый набор с данными.
Список с такими данными выглядит следующим образом:
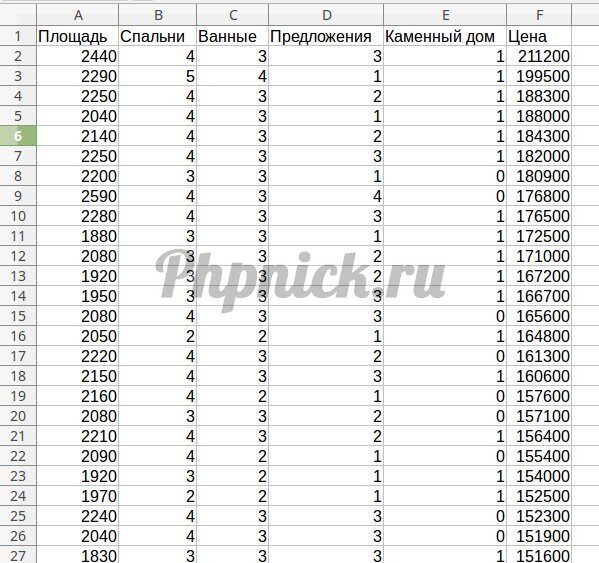
На основе этих учебных данных регрессионную модель сможет в будущем прогнозировать цены домов, при условии, что будут известны первые 5 характеристик (площадь, спальни, ванные, предложения, каменный дом).
Чтобы наглядно увидеть качество работы нашей модели весь набор данных нужно разбить на 2 части. Первая и основная часть нужна для построения модели. Она состоит из 124 строк. Вторая часть содержит несколько строк с данными для проверки качества работы модели. Обычно такие наборы называются как: train-set (основной набор) и test-set (тестовый набор). Оба набора данных хранятся в csv-файлах. С этим форматом данных удобно работать в PHP-ML, потому что там для этого есть специальный класс CsvDataset.
Для вашего удобства выкладываю оба набора с данными. Если будете открывать их в табличном редакторе, то лучше всего подходит LibreOffice.
Итак, скачаем PHP-ML с помощью composer’а:
composer require php-ai/php-ml
После чего в эту папку добавим файлы с готовыми данными.
Далее создадим новый php-файл (можно index.php), и в него добавим следующее содержимое:
<?php
require "vendor/autoload.php";
use Phpml\Dataset\CsvDataset;
use Phpml\Regression\LeastSquares;
$dataset = new CsvDataset('train-data.csv', 5, true);
$samples = $dataset->getSamples();
$targets = $dataset->getTargets();
$regression = new LeastSquares();
$regression->train($samples, $targets);
$predict = $regression->predict([
[1940,3,3,2,1],
[2420,4,3,4,0],
[2150,3,3,5,1],
[1980,2,2,2,0],
]);
print_r($predict);
Здесь я использую только файл train-data.csv, а данные из файла test-data.csv указаны в массиве:
[
[1940,3,3,2,1],
[2420,4,3,4,0],
[2150,3,3,5,1],
[1980,2,2,2,0],
]
Обратите внимание, что в этом массиве, нет колонки с ценами. И нет их здесь потому, что модель должна будет сама спрогнозировать цены по этим данным.
Суть работы кода состоит в том, что мы сначала готовим модель с помощью метода train(), а затем проверяем эффективность ее работы с помощью метода predict().
В данном скрипте мы используем метод наименьших квадратов (Least squares) для получения прогнозируемых цен.
$regression = new LeastSquares();
В результате в браузере мы должны увидеть массив с ценами, очень похожими на цены из файла test-data.csv.
Вот что я увидел в своем браузере:
Array ( [0] => 149963.8126884 [1] => 147411.43475322 [2] => 126097.05458712 [3] => 116334.89652142 )
Здесь первая цифра (149963), довольно далека от тестовой (166500), но остальные цены очень близки:
результат работы кода: 147411, тестовая цена из файла – 147000 результат работы кода: 126097, тестовая цена из файла – 126300 результат работы кода: 116334, тестовая цена из файла – 115900
Об эффективности работы модели судить вам 😊
Кроме «Least squares» бибилиотека еще предлагает нам метод опорных векторов (Support Vector Regression). Результат его работы совсем плохой (с дефолтными настройками):
Array ( [0] => 124854 [1] => 158336 [2] => 139361 [3] => 127603 )
Но можно, конечно, попробовать поэкспериментировать с настройками, и, возможно, результат будет лучше.
Материал с сайта phpnick.ru. Ссылка на материал - https://phpnick.ru/posts/category/php/60