Агентство Искусственного Интеллекта продолжает работу над переводами хороших материалов. Сегодня мы представляет вам перевод заметки «Knowledge Graphs: The Third Era of Computing», которая была опубликована Дэном МакКрири 23 марта этого года. Мы находим этот текст довольно занимательным и полностью отвечающим нашим собственным идеям о гибридной парадигме построения ИИ-систем.
Мой хороший друг Эд Свердлин часто начинает презентацию «Введение в графовые базы данных» с вопроса о том, когда появились вычисления. Он даёт присутствующим несколько попыток угадать, но после их неудачи он показывает изображение клинописной таблички, которая была создана в 3000 году до н. э. Он отмечает, что представление знаний появилось тогда, когда человеку нужно было запомнить что-то действительно важное. Например, Алок должен отдать Сумару 10 корзин зерна.
Смысл в том, что таблицы всегда были отличным способом записать финансовые транзакции. Эти записи несколько эволюционировали, превратились в символы, которые представляли концепции и письменные языки.
Самое интересное то, что эти представления с нами уже более 5 000 лет. Глиняные таблички эволюционировали в свитки из папируса, которые со временем были заменены двойной записью, созданной Лукой Пачоли. В дальнейшем система превратилась в перфокарты, после чего появились приложения на языке программирования COBOL, а затем в хранилища строк, популярные в реляционных базах данных. И сейчас эта система превратилась в ERP-системы, которые управляют многими крупными компаниями.
Табличные представления хорошо показывали себя тогда, когда задачи имели единообразный набор данных. Под единообразностью подразумевается то, что каждая строка имеет аналогичные атрибуты с аналогичными типами данных.
Далее Эд Свердлин задаёт вопрос о том, все ли бизнес-задачи могут быть решены при помощи таблиц? А как насчёт данных о состоянии здоровья? Насколько хорошо электронная медицинская карта может быть перенесена в таблицах. Медицинские данные слишком разнообразны и могут включать в себя список заболеваний, лекарств, вес пациента, фазы его сна, результаты анализа крови, медицинские снимки, данные ЭКГ. Такое разнообразие требует создания огромного количества таблиц, что делает реляционные соединения слишком дорогими.
Каким образом хранятся данные о медицинской карте пациента? Возможно, что при помощи мощного ИИ-агента, который каждую ночь сканирует все ваши данные, и информация об эффективности лекарственных средств посредством IoT поступает в центр обработки данных вашего поставщика или МИС. Что они создают? Ответ прост — список медицинских состояний. И после этого они производят расчёт вероятности того, что пациент обладает одним из них. Эти состояния представляют из себя абстрактные медицинские понятия, такие как «Диабет» или «ХОБЛ». Медицинские системы хранят эти понятия в сложной иерархии (таксономии) со многими связями между ними (онтология). Теперь ваш ИИ-доктор может дать вам некоторые рекомендации о том, что вам стоит делать — сколько шагов пройти, или стоит ли пробовать новый вегетарианский бургер. Таблицы для этих данных не подходят, но зато они отлично вписываются в сети знаний, которые мы привыкли называть графы знаний.
Так как же нам перевести 95 % разработчиков, пишущих на таких языках, как PHP, Java или Python поверх таблиц, в эту новую эру? Возможно, что лучшим способом будет подумать абстрактно над тем, что мы делаем сегодня и разбить эти действия на части.
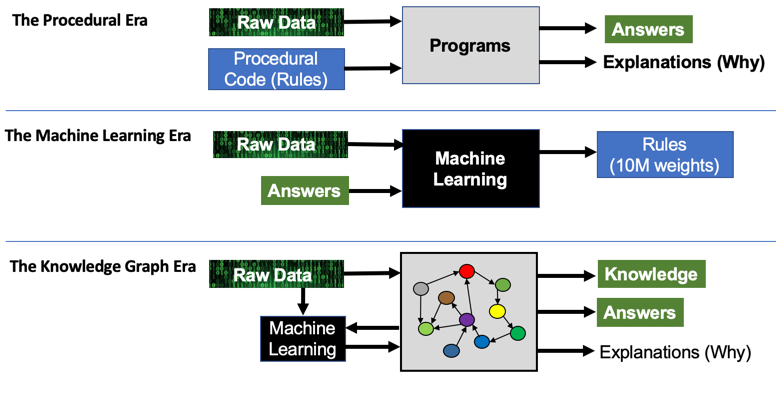
Начнём с давних времён. Первым методом, который использовался для представления знаний, были процедурные правила. Поэтому мы назовём ту эру«Процедурная».

Так разработчики вручную пишут пошаговые процедуры, которые используют необработанные данные и выдают ответы. Разработчики должны дать чёткие инструкции о том, каким образом интерпретировать 1 или 0. Если вам интересно, почему программа дала тот или иной ответ, то вы можете просмотреть набор конкретных правил, которые были применены к вашей ситуации. Это значительно упрощает объяснение того, как работает система.
Теперь рассмотрим эпоху машинного обучения.
Эра машинного обучения обрела невероятную популярность за последние 7 лет. Для машинного обучения используются мощности видеокарт и алгоритмы глубокого обучения. Наборы правил в эре машинного обучения стали менее явными. Мы лишь предоставляем обучающий набор данных, и машина начинает изучать его. К примеру, можно научить радиоуправляемый автомобиль тому, как он должен вести себя на гоночной трассе. Автомобиль ориентируется по линиям на дороге и отвечает правильным выставлением скорости и управления. Обычно, правила, хранятся в виде набора критериев, которые применяются к входным данным при их перемещении по сети. Основная проблема состоит в том, что распознавание изображений требует много критериев, обычно десятки миллионов. Поэтому получить у системы ответ, что послужило главной причиной для принятия решения, не представляется возможным. Система может выдать вам число критериев, которые были использованы для того, чтобы прийти к решению.
Ну а теперь поговорим о третьей эре вычислений — графах знаний.
Эта эра объединила в себе лучшее, что можно было получить из двух предыдущих эр. Такие системы могут не только обучаться на сложных данных, но и объяснять свои решения. Эта система всё ещё использует машинное обучение для того, чтобы собирать необработанные данные и искать в них закономерности. Машинное обучение пытается найти соответствия в изображениях, тексте и звуке, после чего преобразует их в новые записи в сети знаний, с учётом критериев конфиденциальности.
Далее эти данные могут быть проверены на согласованность и качество при помощи алгоритма графа. Он позволяет получить новые знания, ответы и объяснения того, почему было принято то или иное решение. Граф знаний становится хранилищем семантически точных вершин и отношений со степенью доверия, которые были получены в процессах машинного обучения. Процессы обогащения знаний не идеальны и могут стать причиной появления ложных утверждений, если эта сфера не будет курироваться экспертами проблемной области.
Это куда более точное представление об обработке информации нашим мозгом. Без таблиц, без кода и условий. Лишь реальные концепции и отношения между ними, которые могут быть понятны алгоритмам теории графов.
Но как и в реальности, если человек сталкивается с фейковыми новостями, то он рано или поздно поверит в это. Поэтому нужно постоянно проверять подобные утверждения. Это может быть сложно и дорого, особенно когда ваши графы знаний достигают огромных размеров.