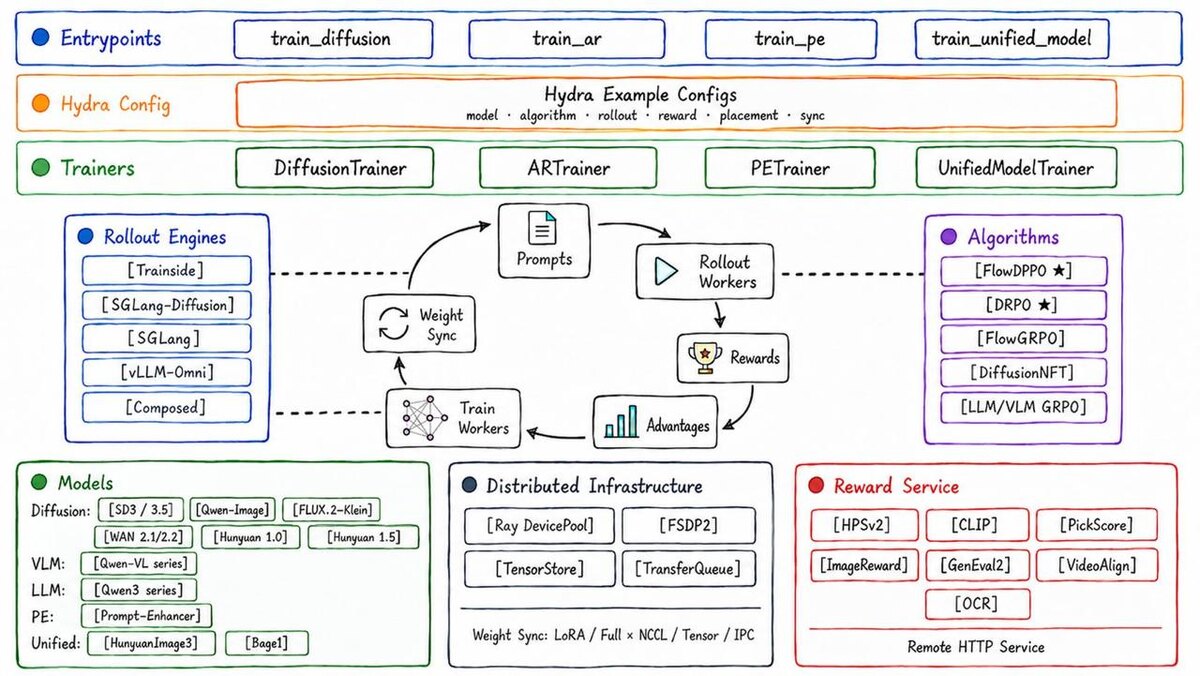
Tencent Hunyuan выкатили UniRL - инфраструктуру для RL-посттрейнинга мультимодальных моделей.
Это попытка собрать один общий RL-цикл для разных семейств моделей: LLM, VLM, diffusion, flow matching и unified multimodal.
Обычный пайплайн выглядит знакомо:
- generate
- score
- advantage
- update
- sync
UniRL пытается сделать этот цикл универсальным. Модель и алгоритм разведены как две независимые оси, поэтому можно комбинировать разные model families и RL-алгоритмы без жёстко зашитого сценария.
Покрытие широкое: text-to-image, text/image-to-video, vision-language, text-only LLM, VLM, LLM-to-diffusion prompt enhancer, а также смешанная autoregressive + diffusion генерация вроде Hunyuan-Image 3 и Bagel.
Есть pluggable rollout engines через единый typed contract: train-side, SGLang, vLLM-Omni. Для масштабирования заявлены FSDP2 sharding и несколько deployment-режимов, которые переключаются из одного конфига.
Отдельно Tencent добавили два своих алгоритма:
- Flow-DPPO - policy optimization для flow/diffusion моделей с trust-region masks на основе exact divergence
- DRPO - RL для LLM со сглаженным advantage-weighted quadratic regularizer
UniRL выглядит как шаг к нормальному post-training стеку для моделей, которые одновременно пишут, видят, генерируют и используют разные типы rollout-движков.
Код: http://github.com/Tencent-Hunyuan/UniRL