Содержание:
- Чем опасны дубли фильтраций и сортировок для Яндекса и Google
- Виды дублей, генерируемых модулями фильтрации и сортировки
- Методы обнаружения скрытых дублей в каталогах
- Стратегия «Белого SEO»
- ЧПУ-фильтры как метод уникализации частичных дублей
- Заключение
Современный интернет-магазин невозможно представить без фильтрации и сортировки товаров (по цене, бренду, цвету). С точки зрения UX — это стандарт качества, но для SEO данный функционал часто становится источником критических технических проблем.
Основная сложность кроется в различии между статическими категориями и динамическими URL. Статическая категория каталога — это постоянный адрес (например, /catalog/smartphones/), оптимизированный под конкретные поисковые запросы. Когда пользователь задействует фильтры, CMS сайта создает новые комбинации параметров, добавляя к базовому адресу GET-переменные: ?sort=price или ?brand=apple.
Для посетителя внешний вид страницы меняется незначительно — перестраивается порядок карточек или отсекаются лишние позиции. Однако поисковые роботы Яндекса и Google воспринимают каждый такой уникальный URL как абсолютно новую, самостоятельную страницу. При множественном пересечении характеристик система начинает лавинообразно генерировать тысячи альтернативных адресов с идентичным контентом.
Масштаб проблемы колоссален: в крупных e-commerce проектах до 30–40% всего объема страниц могут превращаться в подобные мусорные дубликаты. Без жесткого контроля со стороны SEO-специалиста краулеры застревают в бесконечных циклах обработки параметров, ухудшая индексацию реальных товаров и снижая общие позиции сайта в выдаче.

Связаться со мной:
Вконтакте: https://vk.com/oparin_art
WhatsApp: 8 (953) 948-23-85
Telegram: https://t.me/pr_oparin
TenChat: https://tenchat.ru/seo-top
Email почта: pr.oparin@yandex.ru
Youtube: https://www.youtube.com/@seo-oparin
Сразу перейду к делу. А пока подписывайтесь на мой телеграм канал, там я пишу про SEO продвижении в Яндексе и Google, в общем и целом, про интернет-рекламу.
Чем опасны дубли фильтраций и сортировок для Яндекса и Google
Неконтролируемая индексация страниц фильтрации и сортировки наносит серьезный ущерб техническому здоровью сайта и напрямую блокирует рост органического трафика. Поисковые системы Яндекс и Google используют сложные алгоритмы оценки качества структуры каталога, и наличие сотен тысяч мусорных URL активирует сразу несколько негативных факторов ранжирования.
Истощение краулингового бюджета. У каждого сайта есть лимит на количество страниц, которое поисковый робот (краулер) может скачать и проанализировать за один обход. Если модули фильтрации открыты для индексации, робот начинает бесконечно блуждать по динамическим ссылкам вроде ?sort=price&brand=samsung&color=red. В результате краулинговый бюджет расходуется впустую: поисковик не доходит до реальных карточек товаров, новинок или критически важных коммерческих разделов. Сайт перестает оперативно обновляться в поисковом индексе.
Размазывание (каннибализация) ссылочного веса. Внутренний ссылочный вес (PageRank) должен концентрироваться на основных продвигаемых категориях (/catalog/smartphones/). Когда на страницах каталога выводятся десятки ссылок на различные параметры сортировок и комбинации фильтров, внутренний вес «размывается» по этим второстепенным адресам. Поисковые роботы начинают путаться, какая именно страница является наиболее авторитетной для ответа на поисковый запрос пользователя.
Проблема выбора релевантного URL и нестабильность выдачи. Из-за схожести текстового контента (ведь набор товаров на странице сортировки ?sort=popular совпадает с основной категорией) поисковые алгоритмы могут посчитать динамический URL более релевантным, чем статический. Это приводит к постоянному «миганию» позиций в выдаче: в топ-10 попадает то оптимизированная категория, то страница случайного фильтра. Когда в индекс залетает нецелевая страница, падает конверсия, так как пользователь вместо привычного каталога видит хаотичную выборку товаров. В худшем случае Яндекс может признать такие страницы некачественными и наложить на сайт общий фильтр за малополезный контент (МПК).
Виды дублей, генерируемых модулями фильтрации и сортировки
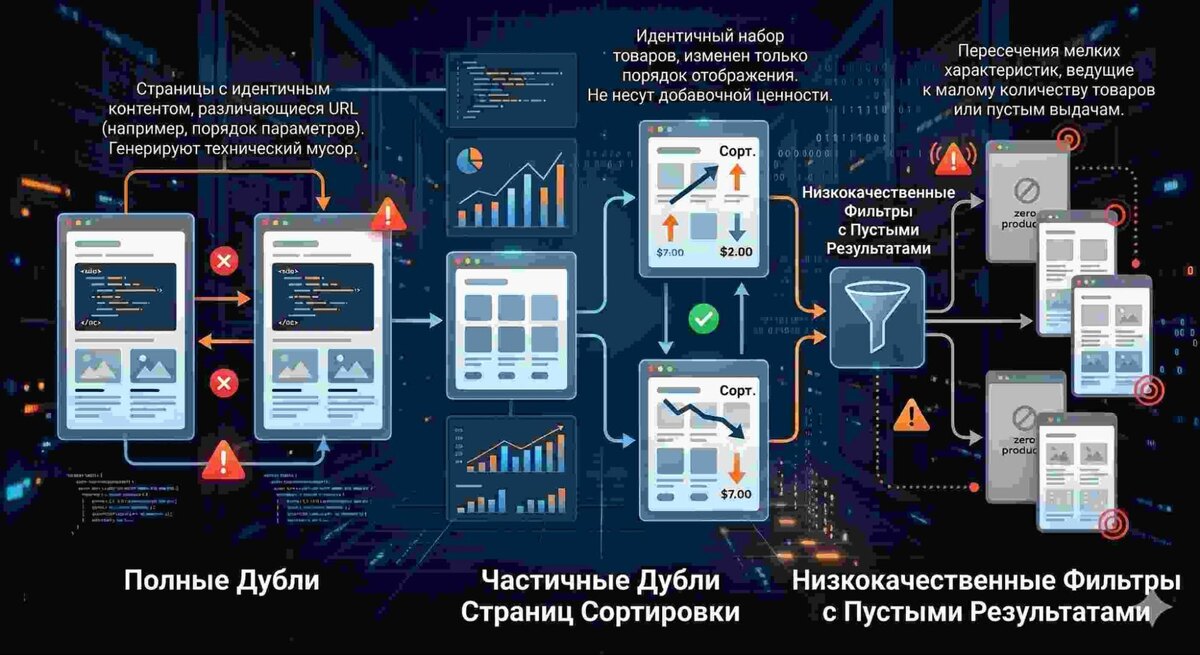
Чтобы эффективно бороться с дублированием контента в каталогах e-commerce, необходимо четко классифицировать возникающие избыточные адреса. Механизмы фильтрации и сортировки создают специфическую группу URL, которую в поисковой оптимизации принято разделять на полные и частичные технические дубликаты. Понимание этой разницы определяет выбор дальнейшего метода их закрытия или оптимизации.
Полные дубли (дублирование порядка GET-параметров). Этот тип дублей возникает, когда состав товаров и контент на странице абсолютно идентичны, но их URL-адреса отличаются из-за последовательности выбора фильтров пользователем или работы скриптов CMS. Например, если покупатель сначала выбрал бренд, а затем цвет, ссылка примет вид: ?brand=apple&color=black. Если же поочередность кликов была обратной, сформируется адрес: ?color=black&brand=apple. Для поисковых роботов Яндекса и Google это две разные веб-страницы. В результате на сайте создаются абсолютно полные дубли, дублирующие не только ассортимент, но и текстовые блоки, заголовки, а также метатеги, что перегружает поисковый индекс.
Частичные дубли страниц сортировок. Данный вид дублирования генерируется инструментами изменения порядка отображения листинга товаров. Когда пользователь сортирует продукцию по цене (?sort=price), популярности (?sort=popular) или алфавиту, текстовое наполнение страницы, ее структура, базовые метатеги (Title, Description) и сам пул товарных карточек остаются прежними. Меняется лишь визуальная последовательность блоков. Такие страницы несут нулевую добавочную ценность для поисковых систем, поскольку удовлетворяют один и тот же интент пользователя, но при этом активно индексируются и конкурируют с основной статической категорией, размывая ее релевантность.
Мусорные фильтры с низким ассортиментом или дублированием интента. Сюда относятся URL, создаваемые при пересечении слишком мелких, малозначимых характеристик или свойств, которые не подкреплены реальным поисковым спросом. Специфика e-commerce такова, что при выборе нескольких узких фильтров (например, конкретный неочевидный размер в комбинации со специфическим материалом) страница может содержать всего 1–2 товара или вовсе оказаться пустой. Индексация страниц с единичным ассортиментом или повторяющимся текстовым составом крайне опасна: Яндекс классифицирует подобные URL как малополезный контент (МПК) и может исключить их из поиска вместе с ухудшением общей оценки качества всего домена.
Методы обнаружения скрытых дублей в каталогах
Для качественной очистки e-commerce проекта от технического мусора SEO-специалисту необходимо провести комплексный аудит. Поиск скрытых страниц фильтрации и сортировки, которые уже проиндексированы или доступны для роботов, строится на комбинации трех основных подходов: профессионального сканирования, анализа панелей вебмастеров и использования точечных поисковых операторов.
Специализированные краулеры (Screaming Frog SEO Spider, SiteAnalyzer). Настройка технического сканирования — первый шаг в обнаружении дубликатов. Чтобы выявить мусорные URL, в настройках парсера необходимо временно разрешить обход параметров (убедившись, что сканер игнорирует стандартные инструкции robots.txt, если они уже прописаны). После завершения сканирования анализируется вкладка URL или Duplicate. Сортировка адресов по наличию знаков вопроса (?) позволяет моментально выгрузить все страницы с GET-переменными. Особое внимание следует уделить поиску страниц с одинаковым хешем (содержимым) или идентичными заголовками H1 и Title, но разными динамическими адресами.
Анализ панелей вебмастеров (Яндекс.Вебмастер и Google Search Console). Реальную картину того, что поисковые системы уже добавили в свой индекс, дают официальные панели для вебмастеров. В Google Search Console необходимо изучить раздел «Страницы» и проверить статус «Исключено» (в частности, пункты «Страница является копией, каноническая не выбрана пользователем» или «Сканировано, но не проиндексировано»). В Яндекс.Вебмастере ключевым источником данных является раздел «Индексирование» -> «Страницы в поиске» или «Исключенные страницы» с фильтром по статусу «Дубль». Если в списке присутствуют URL с хвостами ?sort=, ?p= или ?filter=, значит, роботы уже тратят на них краулинговый бюджет.
Использование поисковых операторов и ручной аудит. Когда нужно точечно проверить конкретную категорию на наличие скрытого индекса, применяются операторы поисковых систем. Запрос вида site:вашсайт.ру inurl:?sort или site:вашсайт.ру/catalog/smartphones/ в комбинации с текстовыми маркерами позволяет увидеть все проиндексированные комбинации параметров.
Если вы обнаружили, что совершенно разные по логике страницы признаются поисковиком дублями и исключаются, необходимо глубоко изучить их историю. Часто это связано с тем, что в момент визита робота сервер отдавал ошибку или некорректный контент. Чтобы докопаться до сути, в Яндексе используют оператор url:. Найдя с его помощью проблемный адрес, важно тщательно проверить сохраненную копию страницы — именно там отображается тот текстовый контент, который зафиксировал робот при последнем обходе. Параллельно через инструмент «Проверка ответа сервера» оценивается текущее состояние URL: если сейчас страницы отдают корректный и уникальный контент, их необходимо отправить на ручной переобход в вебмастере, чтобы ускорить процесс их возвращения в поиск и исправления ошибок склейки.
Стратегия «Белого SEO»: 5 способов технического решения проблемы
Выбор метода устранения дубликатов зависит от структуры каталога, используемой CMS и того, должен ли конкретный URL привлекать поисковый трафик. В рамках «белого» SEO применяются пять основных инженерных решений, которые позволяют навести технический порядок в каталоге, не нарушая правил поисковых систем.
Метод №1: Атрибут rel="canonical"
Указание канонического адреса — один из самых гибких инструментов в e-commerce. С его помощью SEO-специалист явно сообщает поисковым роботам, какую страницу считать главной (эталонной), а какие — ее второстепенными копиями.
- Как это работает: На всех страницах сортировок (например, /catalog/smartphones/?sort=price) и неочевидных фильтраций в блоке <head> прописывается тег: <link rel="canonical" href="https://site.ru/catalog/smartphones/" />.
- Плюсы: Краулеры индексируют только основную категорию, но при этом передают ей ссылочный вес со всех динамических URL.
- Минусы и риски: Google воспринимает canonical не как жесткую директиву, а как рекомендацию. Если контент на странице фильтра сильно отличается от основной категории (например, отфильтровано всего 2 товара из 200), Google может проигнорировать тег и все равно добавить дубль в индекс.
Метод №2: Метатег robots со значением noindex, follow
Этот способ оптимален для закрытия страниц сортировки и комбинаций фильтров, которые не имеют коммерческого потенциала, но содержат ссылки на конечные карточки товаров.
- Как это работает: В код динамических страниц внедряется тег: <meta name="robots" content="noindex, follow" />.
- Плюсы: Директива noindex является строго обязательной как для Яндекса, так и для Google — страницы гарантированно исчезнут из выдачи. При этом атрибут follow разрешает роботу переходить по ссылкам, расположенным на этой странице, благодаря чему краулеры находят и индексируют карточки товаров.
- Минусы: Метод не экономит краулинговый бюджет мгновенно: роботу все равно нужно зайти на страницу, скачать ее код и только потом обнаружить запрет на индексацию.
Метод №3: Директива Clean-param в файле robots.txt
Специализированный инструмент, созданный программистами Яндекса для эффективного очищения индекса от дублирующихся GET-параметров в интернет-магазинах.
- Как это работает: В файле robots.txt прописывается межпрограммная команда, указывающая, какие переменные не изменяют контент страницы, а лишь перестраивают его. Пример синтаксиса: Clean-param: sort /catalog/.
- Плюсы: Колоссальная экономия краулингового бюджета Яндекса. Робот объединяет адреса еще на этапе подготовки к обходу и не скачивает дублирующиеся страницы по многу раз.
- Минусы: Директива обрабатывается исключительно Яндексом. Робот Google полностью игнорирует Clean-param, поэтому данный метод нельзя использовать как единственное решение.
Метод №4: Жесткое закрытие через Disallow в robots.txt
Прямой запрет на сканирование определенных папок или параметров в главном конфигурационном файле сайта.
- Как это работает: В файл добавляется инструкция для блокировки всех URL, содержащих знак вопроса или конкретные маркеры: Disallow: /*?sort= или Disallow: /*?filter=.
- Плюсы: Максимально простая реализация, которая мгновенно останавливает сканирование мусорных страниц роботами.
- Минусы: Этот метод несет в себе скрытые риски. Если страница фильтра была закрыта через Disallow, но на нее ведут внешние или внутренние ссылки, Google может добавить её в индекс с пометкой «Индексирование разрешено, но описание недоступно». Кроме того, закрыв страницу от обхода, вы закрываете от робота и ссылки на товары, ухудшая индексацию новинок.
Метод №5: Перевод фильтрации на AJAX / JavaScript
Наиболее прогрессивный и технически чистый подход с точки зрения классического SEO-аудита.
- Как это работает: При клике пользователя на фильтр или сортировку страница не перезагружается с созданием нового URL. Запрос обрабатывается скриптом на стороне браузера (AJAX), который обновляет только сетку товаров. При этом для пользователя в URL может добавляться хэш (например, #/sort=price), который поисковыми роботами по умолчанию игнорируется.
- Плюсы: Полное отсутствие физических дублей страниц в коде сайта. Роботы видят только чистые статические категории, краулинговый бюджет расходуется идеально.
- Минусы: Требует привлечения опытных frontend- и backend-разработчиков. Сложно реализовать, если в будущем часть этих фильтров понадобится открыть для сбора низкочастотного трафика.
ЧПУ-фильтры (Посадочные страницы) как метод уникализации частичных дублей
В практике поискового продвижения крупных интернет-магазинов существует группа страниц фильтрации, которую категорически запрещено закрывать от индексации. Речь идет о комбинациях параметров, соответствующих реальному коммерческому спросу пользователей в поисковых системах. Например, если базовая категория — это /catalog/smartphones/, то пересечение фильтров «Apple» и «128 Гб» формирует устойчивый низкочастотный и среднечастотный спрос («купить айфон на 128 гб»). Оставлять такие страницы в виде динамических URL с техническими хвостами неэффективно, а закрывать их — значит добровольно отдавать трафик конкурентам. Решением становится создание SEO-фильтров с ЧПУ (человекопонятным URL).
Когда фильтр нужно превращать в посадочную страницу. Перевод динамического фильтра в статус полноценной статической страницы оправдан только тогда, когда под эту комбинацию характеристик существует собранное семантическое ядро (запросы в Яндекс.Вордстат или Google Keyword Planner). Если у комбинации параметров есть ненулевая частотность, технический дубль должен быть уникализирован и оптимизирован. Все остальные пересечения фильтров, не имеющие спроса (например, сортировка по цвету «фиолетовый» вперемешку с весом товара и типом упаковки), по-прежнему закрываются методами из предыдущего раздела.
Правила генерации ЧПУ для SEO-фильтров. Чтобы поисковые роботы корректно ранжировали страницу фильтра, её адрес должен быть переведен из динамического вида в статический с понятной вложенностью. Вместо адреса /catalog/smartphones/?brand=apple&storage=128gb настраивается серверный редирект (или бесшовная генерация) на ЧПУ-адрес вида /catalog/smartphones/apple/128gb/ или /catalog/smartphones/apple-128gb/. Такая структура URL передает больше доверия поисковым системам, лучше воспринимается пользователями в выдаче (повышает CTR) и позволяет эффективно распределять внутренний ссылочный вес.
Механика уникализации открытых трафиковых страниц. Главная опасность открытия страниц фильтрации для индекса — это автоматическое создание дубликатов заголовков и метатегов. Если 50 разных страниц фильтров будут иметь одинаковый Title, сайт быстро попадет под санкции за неуникальный контент. Для превращения частичного дубля в качественную посадочную страницу внедряются следующие правила автоматизации:
- Шаблонная генерация метатегов (Title, Description). Настраиваются строгие правила масок. Например: «[Категория] [Свойство 1] [Свойство 2] купить в интернет-магазине...». Для нашего примера: «Смартфоны Apple 128Gb купить в Москве...».
- Динамическое изменение заголовка H1. Заголовок страницы должен четко отражать суть выборки: «Смартфоны Apple на 128 Гб».
- Уникализация текстового блока. Если на сайте предусмотрены SEO-тексты для категорий, они ни в коем случае не должны дублироваться на страницах фильтров. На ЧПУ-фильтрах либо выводятся уникальные небольшие тексты-описания, либо текстовый блок базовой категории полностью скрывается, чтобы избежать текстового наложения.
- Настройка хлебных крошек. Навигационная цепочка должна логично вести пользователя и робота обратно в основную категорию, закрепляя правильную техническую иерарсию сайта.
Заключение и Чек-лист для SEO-специалиста
Работа с дубликатами страниц, возникающими из-за модулей фильтрации и сортировки — это непрерывный процесс технического контроля. Понимание природы поисковых роботов и архитектуры каталога позволяет SEO-специалисту не просто «закрывать всё подряд», а гибко управлять индексацией, балансируя между идеальным UX для клиентов и безупречной чистотой кода для Яндекса и Google.
Грамотное избавление от дублированного контента и оптимизация краулингового бюджета всегда способствуют органическому росту позиций и увеличению целевого трафика. Чтобы закрепить материал на практике, используйте пошаговый чек-лист технического аудита каталога.
Пошаговый чек-лист по ликвидации дублей фильтрации
- Сбор семантики и выявление спроса: Перед началом любых технических работ соберите семантическое ядро для категорий. Определите, какие комбинации фильтров имеют реальную частотность в поисковых системах.
- Проектирование SEO-фильтров: Все комбинации параметров, под которые есть поисковый спрос, переведите на статические ЧПУ-адреса. Настройте для них автоматическую генерацию уникальных метатегов (Title, Description) по маскам, динамические заголовки H1 и уникализируйте текстовые блоки (скройте или удалите тексты базовой категории на страницах фильтров).
- Изоляция мусорных параметров: Все остальные динамические страницы (сортировки, пустые или низкоассортиментные фильтры, хаотичные пересечения параметров) закройте от индексации. Выберите оптимальный метод под вашу CMS: атрибут rel="canonical", метатег noindex, follow (чтобы роботы продолжали обходить карточки товаров) или директиву Clean-param для Яндекса.
- Технический мониторинг выдачи: Регулярно сканируйте сайт через Screaming Frog или SiteAnalyzer и проверяйте панели вебмастеров. Помните, что пока поисковый робот физически не посетит страницу, с которой настроена склейка или закрытие, она продолжит отображаться в поиске. Если в индексе зависла старая страница-дубль, самый быстрый и оптимальный способ убрать её — отправить URL на переобход в ручном режиме через панели вебмастеров.
Параллельно с чисткой фильтрации всегда проводите комплексную оптимизацию сайта по другим направлениям (скорость загрузки, коммерческие факторы, мобильная адаптивность), так как только системный подход в рамках «белого» SEO дает максимальный синергетический эффект для продвижения интернет-магазина.
Связаться со мной:
Вконтакте: https://vk.com/oparin_art
WhatsApp: 8 (953) 948-23-85
Telegram: https://t.me/pr_oparin
TenChat: https://tenchat.ru/seo-top
Email почта: pr.oparin@yandex.ru
Youtube: https://www.youtube.com/@seo-oparin