
Фрилансеру, разработчику или соло-предпринимателю часто нужно следить за своей нишей: новые инструменты, обновления сервисов, тренды, кейсы конкурентов, изменения в технологиях. Проблема в том, что ручной мониторинг быстро превращается в отдельную работу: нужно открыть десятки вкладок, выбрать важное, кратко пересказать и сохранить выводы
Я решил автоматизировать этот процесс и собрать локального AI-агента, который сам ищет свежие новости по заданной теме, анализирует найденные материалы и формирует готовый Markdown-отчёт
В этом примере использую Docker Agent, Brave Search API, Docker Model Runner и локальную модель Qwen3.5-4B. Brave Search отвечает за поиск актуальных статей, skill описывает пошаговую логику работы, а локальная модель помогает превратить найденные материалы в понятный обзор
Такой подход особенно полезен, если вы регулярно готовите контент, следите за рынком, пишете клиентские отчёты или хотите экономить кредиты внешних AI-сервисов. Рабочий процесс остаётся локальным, а результат можно сохранить в Markdown и использовать как основу для статьи, поста, рассылки или внутренней базы знаний
Как работает схема
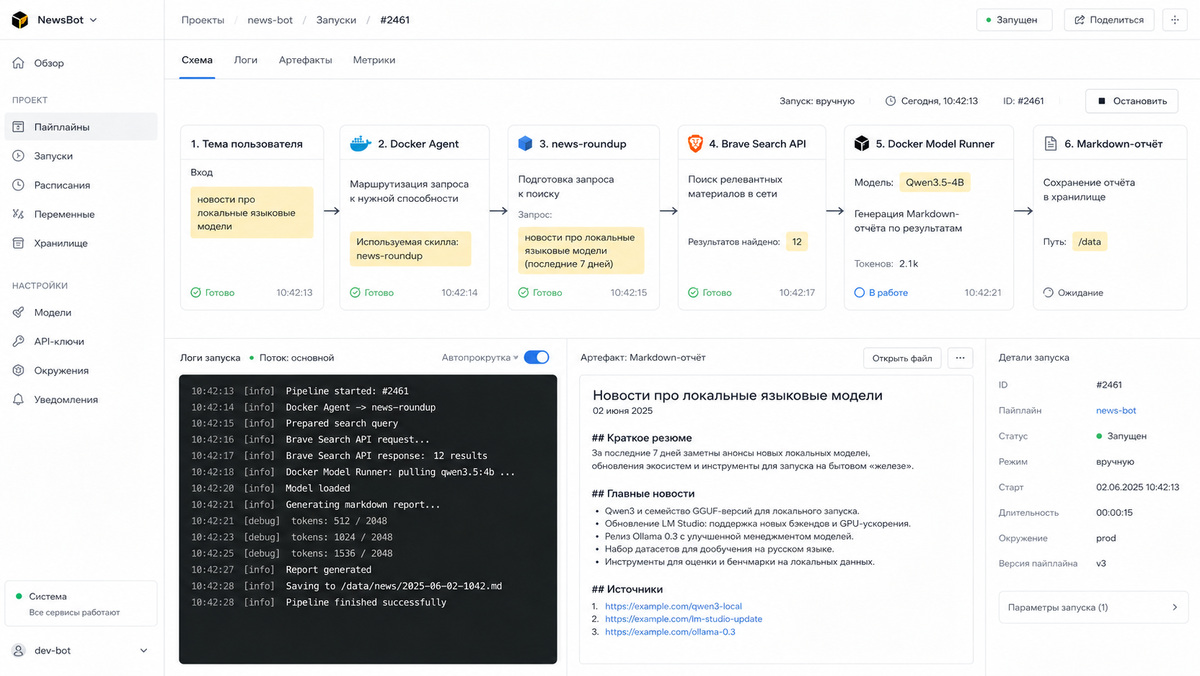
Логика довольно простая
Сначала пользователь задаёт тему, например: «новости про маленькие языковые модели» или «свежие материалы про Docker Agent»
После этого Docker Agent активирует специальный skill. Skill обращается к Brave Search API и ищет свежие новости по заданной теме
Затем для каждой найденной статьи можно дополнительно собрать расширенный контекст: источник, URL, дату публикации, похожие материалы и дополнительные веб-результаты
После этого локальная модель анализирует найденные материалы и формирует Markdown-отчёт: краткое резюме, список статей, основные выводы и ключевые тренды
В итоге получается не просто список ссылок, а готовая подборка главного по нужной теме
Что нужно для запуска
Для такого сценария понадобится несколько компонентов.
Во-первых, Docker и Docker Compose. Без них агент и окружение не запустятся
Во-вторых, аккаунт Brave Search и API-ключ. Brave Search API нужен для получения свежих новостей в структурированном виде. У Brave есть бесплатный тариф, которого достаточно для базовых экспериментов.
В-третьих, локальная модель с большим контекстным окном и поддержкой вызовов функций. В моём случае я использовал Qwen3.5-4B от Qwen в версии Unsloth
Я начинал тесты с Qwen3.5-9B, но на MacBook Air она работала медленнее. Qwen3.5-4B оказалась более практичным вариантом для повседневного использования: она достаточно хорошо справляется с анализом и генерацией текста, но при этом не так сильно нагружает железо.
Пошаговая настройка Docker Agent для подборки новостей
Теперь перейдём к самой настройке
В этом примере мы собираем агента, который будет запускаться в Docker, использовать Brave Search API для поиска новостей и локальную модель для подготовки отчёта
Шаг 1. Создаём Dockerfile для Docker Agent
Я использовал базовый образ Ubuntu 22.04, установил curl для запросов к Brave Search API и скопировал бинарный файл docker-agent из образа docker/docker-agent:1.32.5
Пример Dockerfile:
FROM --platform=$BUILDPLATFORM docker/docker-agent:1.32.5 AS coding-agent
FROM --platform=$BUILDPLATFORM ubuntu:22.04 AS base
LABEL maintainer="@k33g_org"
ARG TARGETOS
ARG TARGETARCH
ARG USER_NAME=docker-agent-user
ARG DEBIAN_FRONTEND=noninteractive
ENV LANG=en_US.UTF-8
ENV LANGUAGE=en_US.UTF-8
ENV LC_COLLATE=C
ENV LC_CTYPE=en_US.UTF-8
# Install tools
RUN <<EOF
apt-get update
apt-get install -y wget curl
apt-get clean autoclean
apt-get autoremove --yes
rm -rf /var/lib/{apt,dpkg,cache,log}/
EOF
# Install docker-agent
COPY --from=coding-agent /docker-agent /usr/local/bin/docker-agent
# Create a new user
RUN adduser ${USER_NAME}
# Set the working directory
WORKDIR /home/${USER_NAME}
# Set the owner of the working directory
RUN chown -R ${USER_NAME}:${USER_NAME} /home/${USER_NAME}
# Switch to the regular user
USER ${USER_NAME}
Здесь важно, что внутри контейнера уже будет curl. Он нужен для выполнения запросов к Brave Search API
Шаг 2. Создаём файл конфигурации Docker Agent
Дальше нужно настроить самого агента.
В конфигурации я использую корневого агента с моделью brain. Это псевдоним для локальной модели Qwen3.5-4B. Также включаю поддержку skills, потому что именно skill будет описывать пошаговую механику поиска и подготовки отчёта.
Задача агента — вести себя как технический редактор или IT-журналист: находить новости, выделять главное, объяснять контекст и формировать аккуратный отчёт.
Пример логики конфигурации:
agents:
root:
model: brain
description: Эксперт по подборкам технологических новостей
skills: true
instruction: |
Вы IT-журналист с хорошим пониманием программной инженерии,
облачных технологий, искусственного интеллекта, кибербезопасности
и open source.
Ваша задача — находить свежие технологические новости,
анализировать их и объяснять главное простым, точным языком.
Для каждой новости нужно дать контекст:
что произошло, почему это важно и кому это может быть полезно.
Для набора инструментов Docker Agent можно использовать готовые варианты, но в этом примере удобнее использовать script-подход с командой execute_command
Так агент сможет выполнять команды оболочки, запускать curl-запросы к Brave Search API и сохранять результат.
Это проще, чем писать отдельный полноценный инструмент с нуля
Шаг 3. Создаём skill для поиска новостей
Теперь создадим skill, который будет отвечать за подборку новостей.
Я назвал его news-roundup. Его задача — взять тему пользователя, найти свежие новости через Brave Search API, обогатить результаты и сформировать Markdown-отчёт.
Структура папок может выглядеть так:
.agents
└── skills
└── news-roundup
└── SKILL.md
Внутри файла SKILL.md описываем, что должен делать агент.
Пример содержимого:
---
name: news-roundup
description: Search for recent news on a given topic, enrich articles and generate a Markdown report.
---
# News Roundup
## Goal
You are a technical news assistant.
Your task is to search for recent news on the topic provided by the user, enrich the results with additional context and generate a structured Markdown report.
The final report should be clear, concise and useful for IT professionals, freelancers, solo founders and technical content creators.
## Steps
### Step 1 — Search for recent news
Use Brave Search API to find recent news articles.
Command to execute:
```bash
curl -s "https://api.search.brave.com/res/v1/news/search?q=$(echo "$ARGUMENTS_REST" | sed 's/ /+/g')&count=3&freshness=pw" \
-H "X-Subscription-Token: ${BRAVE}" \
-H "Accept: application/json"
Смысл skill в том, что мы не просто просим модель «найти новости». Мы явно описываем процесс: сначала поиск, потом обогащение, потом генерация отчёта.
Так агент работает более предсказуемо
Шаг 4. Подключаем compose.yml
Теперь нужно подготовить compose.yml, через который будет запускаться агент.
Также понадобится файл .env, где будет храниться API-ключ Brave Search:
BRAVE=abcdef1234567890
Вместо abcdef1234567890 нужно подставить свой реальный API-ключ.
Общая идея такая: контейнер получает доступ к переменной BRAVE, видит папку со skills и может сохранять готовые отчёты в папку data.
Перед запуском лучше заранее создать папку для отчётов:
mkdir -p data
Если папки data не будет, Docker может не смонтировать том так, как вы ожидаете
Шаг 5. Запускаем и тестируем агента
После настройки можно запустить агента через Docker Compose
Затем задаём ему запрос, например:
Используй skill для подборки новостей про маленькие языковые модели.
Или:
Собери краткий обзор свежих новостей про Docker Agent
После этого агент должен выполнить skill news-roundup, обратиться к Brave Search API, найти свежие статьи, проанализировать их и сформировать отчёт в Markdown
В зависимости от модели и железа первый запуск может занять несколько минут. Это нормально: локальная модель работает медленнее, чем облачные сервисы, зато вы не тратите кредиты Claude или других внешних AI-инструментов
В конце агент должен выдать путь к сгенерированному файлу. Обычно отчёт сохраняется в папку data с именем в формате:
news-report-YYYYMMDD-HHMMSS.md
Такой файл можно открыть, отредактировать и использовать дальше: для статьи, поста, рассылки, внутреннего отчёта или базы знаний.
Что получается на выходе
На выходе мы получаем не просто список ссылок, а структурированную подборку.
В хорошем отчёте должны быть:
- тема подборки;
- дата генерации;
- краткое резюме;
- список найденных статей;
- источник и URL каждой статьи;
- дата публикации;
- краткое объяснение, почему материал важен;
- основные тренды;
- выводы для практического применения.
Для фрилансера или соло-предпринимателя это особенно удобно. Можно быстро понять, что происходит в нише, не тратя время на ручной поиск и первичную фильтрацию.
Выбор модели
Я начинал с Qwen3.5-9B, но на MacBook Air она работала заметно медленнее.
Qwen3.5-4B оказалась более практичным выбором для регулярного использования. Она быстрее запускается, меньше нагружает систему и при этом нормально справляется с задачей краткого анализа новостей.
Если у вас более мощное железо, можно попробовать модель крупнее. Если работаете на ноутбуке, лучше начать с более лёгкой модели.
Подтверждение команд
По умолчанию агент может запрашивать подтверждение перед каждым вызовом команды.
Это полезно на этапе тестирования, потому что вы видите, что именно он собирается выполнить.
Но если вы хотите полностью автоматический режим, это поведение можно изменить в настройках.
На первом этапе я бы не отключал подтверждения полностью. Сначала лучше убедиться, что все curl-запросы выглядят правильно и агент не делает лишних действий.
Параметр freshness
В skill используется параметр:
freshness=pw
Он означает, что Brave Search API будет искать материалы за прошедшую неделю.
Если вам нужны совсем свежие новости, этот параметр можно изменить. Если нужен более широкий обзор, тоже можно расширить период.
Для регулярных еженедельных подборок freshness=pw — удобный вариант.
Папка data
Папку data лучше создать заранее.
Если она не существует до запуска контейнера, можно получить ошибку или не увидеть итоговый отчёт там, где вы его ожидаете.
Команда простая:
mkdir -p data
После этого отчёты будут сохраняться в понятном месте и останутся доступны после завершения работы контейнера.
Почему Brave Search API, а не обычный парсинг сайтов
Можно было бы пытаться парсить страницы вручную, но это менее надёжный путь.
Brave Search API возвращает структурированные данные: заголовок, источник, URL, дату публикации и другие метаданные. Это удобнее, чем разбирать HTML, обходить защиту сайтов и каждый раз адаптироваться под разную структуру страниц.
Для такого сценария API — более стабильный и понятный вариант.
Почему локальная модель, а не Claude или ChatGPT
Облачные модели часто дают более сильный результат, особенно если нужен глубокий анализ или качественная редактура.
Но у локального подхода есть свои преимущества.
Во-первых, можно экономить кредиты внешних AI-сервисов.
Во-вторых, можно запускать повторяющиеся задачи локально.
В-третьих, такая схема хорошо подходит для экспериментов с агентами, skills и автоматизацией рабочих процессов.
Я не считаю, что локальная модель полностью заменяет Claude или ChatGPT. Скорее, это другой класс задач. Для регулярной первичной обработки, сбора материалов и подготовки чернового отчёта локального агента может быть достаточно.
А уже финальную редактуру, если нужно, можно делать отдельно
В итоге мы получаем локального агента, который умеет искать свежие новости по теме, обогащать результаты дополнительными источниками и собирать структурированный Markdown-отчёт
Да, такая схема требует базового понимания Docker и настройки окружения. Но для технического фрилансера, соло-разработчика, маркетолога с техническим уклоном или автора IT-контента это может стать удобным способом автоматизировать регулярный мониторинг ниши.
Главная ценность здесь не в том, что мы просто запускаем Docker Agent. Главная ценность в том, что мы превращаем повторяющуюся информационную рутину в воспроизводимый локальный процесс: задали тему, получили обзор, сохранили результат и используем его дальше в работе без трат токенов
Задали тему — получили подборку
Сохранили отчёт — использовали его для статьи, поста, рассылки или клиентского обзора.
Повторили процесс — получили регулярный поток материалов без ручного поиска с нуля.
Для меня это хороший пример того, как локальные модели и агентные инструменты можно использовать не ради эксперимента, а для вполне практичной задачи: быстро собирать и структурировать информацию