Содержание:
- Факторы формирования бюджета
- Аудит и диагностика: Как понять, куда «утекает» бюджет
- Техническая оптимизация структуры
- Борьба с «пожирателями» бюджета
- Производительность и серверные технологии как ускорители индексации
- Продвинутая перелинковка для распределения краулингового приоритета
- Заключение
Краулинговый бюджет (Crawl Budget) — это лимит на количество URL-адресов, которые поисковый робот (краулер) готов и способен просканировать на конкретном веб-ресурсе в течение суток. Поисковые системы, такие как Google и Яндекс, не обладают бесконечными вычислительными мощностями, поэтому они вынуждены распределять свои ресурсы между миллионами площадок. Когда бот заходит на сайт, он заранее «знает», какой объем данных он может обработать без создания критической нагрузки на сервер и собственных систем.
Для небольших сайтов (до нескольких тысяч страниц) понятие бюджета часто остается абстрактным, так как поисковик в любом случае проиндексирует весь доступный контент, который обычно не превышает действующие квоты. Однако ситуация кардинально меняется для Enterprise-проектов с объемом 10 000+ страниц, интернет-магазинов с огромным ассортиментом или динамических порталов с постоянными обновлениями.

Связаться со мной:
Вконтакте: https://vk.com/oparin_art
WhatsApp: 8 (953) 948-23-85
Telegram: https://t.me/pr_oparin
TenChat: https://tenchat.ru/seo-top
Email почта: pr.oparin@yandex.ru
Youtube: https://www.youtube.com/@seo-oparin
Сразу перейду к делу. А пока подписывайтесь на мой телеграм канал, там я пишу про SEO продвижении в Яндексе и Google, в общем и целом, про интернет-рекламу.
Факторы формирования бюджета: Как поисковики оценивают ваш ресурс
Объем краулингового бюджета не является статичной величиной; это динамическая метрика, которую поисковые системы рассчитывают индивидуально для каждого домена. Понимание механизмов этого расчета позволяет SEO-специалисту влиять на лимиты через конкретные технические и контентные показатели.
Авторитетность и качество контента как фундамент квоты Ключевым параметром при определении лимита выступает общая авторитетность сайта. Поисковые системы анализируют исторические данные о качестве материалов, пользовательские сигналы и общий индекс качества ресурса (ИКС).
- Спрос на контент: Если страницы сайта востребованы пользователями и регулярно обновляются, роботы будут посещать их чаще для поддержания актуальности выдачи.
- Частота обновлений: Редкое внесение изменений в разделы ведет к тому, что краулеры начинают заходить на проект реже, постепенно сокращая лимиты.
Техническое «здоровье» и производительность сервера Способность сервера быстро и без ошибок обрабатывать запросы напрямую определяет интенсивность сканирования.
- Время отклика (TTFB): Для обеспечения оптимального сканирования время ответа сервера (Time To First Byte) должно стабильно находиться в пределах 200–500 мс. Существенное замедление работы сервера вынуждает краулеров сокращать лимиты, чтобы не создавать критическую нагрузку на хост.
- Стабильность: Систематические сбои в работе сервера (коды 5xx) во время заходов бота — один из самых негативных факторов, приводящий к резкому падению бюджета.
Влияние ссылочного профиля
Ссылки служат для поисковых роботов «дорожной картой», определяющей приоритетность обхода.
- Внешние ссылки: Страницы с высоким весом и большим количеством качественных внешних линков сканируются значительно чаще.
- Внутренняя перелинковка: Грамотное распределение внутренних ссылок позволяет «направлять» робота с популярных страниц на новые или менее посещаемые узлы, ускоряя их индексацию. Чем меньше ссылок ведет на конкретный URL, тем ниже вероятность его регулярного обхода.
Таким образом, краулинговый бюджет — это баланс между технической готовностью вашего сервера и доверием поисковой системы к ценности вашего контента.
Аудит и диагностика: Как понять, куда «утекает» бюджет
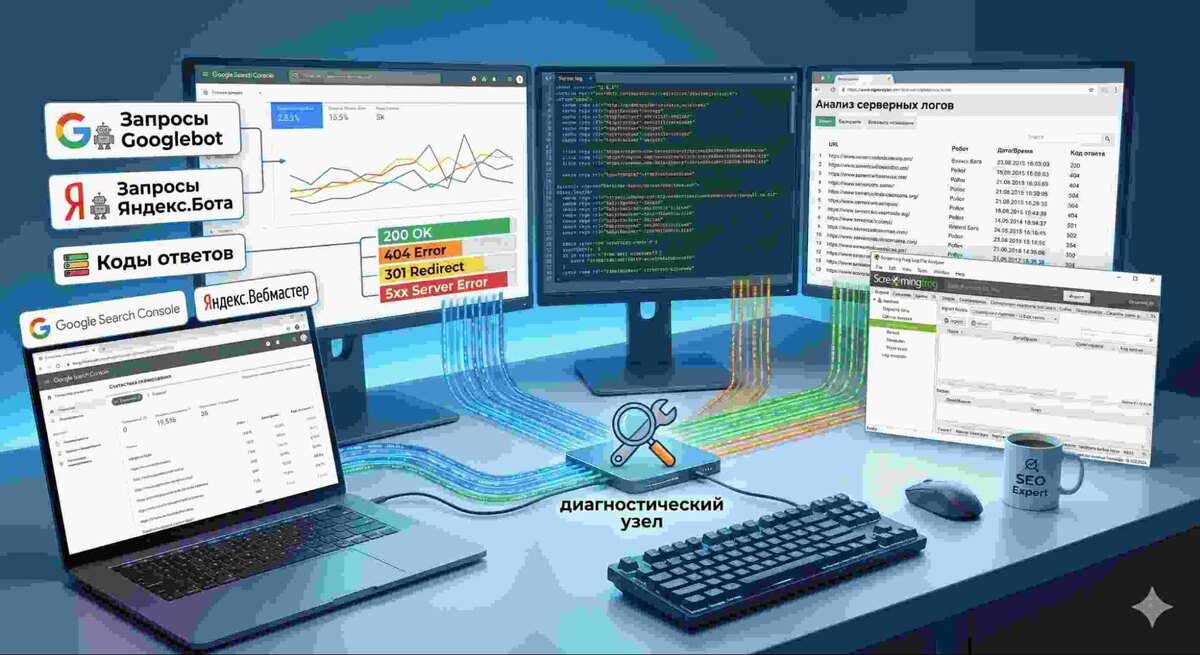
Для эффективного управления краулинговым бюджетом на крупных проектах недостаточно использовать только стандартные SEO-сервисы. Необходимо сопоставить то, что мы «даем» поисковику, с тем, что он реально «забирает».
Анализ серверных логов (access logs) — «золотой стандарт» мониторинга Лог-файлы сервера — это единственный первоисточник данных, который показывает 100% обращений роботов. В отличие от систем аналитики, логи фиксируют каждый запрос к файлам стилей, скриптам и документам, которые не имеют счетчиков посещаемости.
- Что искать в логах: Частоту заходов Googlebot и YandexBot на конкретные типы страниц, распределение запросов по кодам ответа (200, 301, 404, 5xx) и объем скачиваемого трафика.
- Инструменты: Для обработки больших массивов данных (логов сайта в 10 000+ страниц) используются специализированные анализаторы, такие как Screaming Frog Log File Analyser, JetOctopus или Botify.
Работа с панелями для вебмастеров Google Search Console и Яндекс.Вебмастер предоставляют агрегированные данные, которые служат отличным индикатором «здоровья» краулинга.
- Google Search Console: В отчете «Индексирование страниц» важно отслеживать график «Общее количество запросов на сканирование». Резкие скачки могут сигнализировать о появлении бесконечных циклов или генерации дублей, а падения — о проблемах с доступностью сервера.
- Яндекс.Вебмастер: Раздел «Статистика обхода» позволяет увидеть, какие именно URL робот посетил за последние дни и какие вердикты им выставил.
Ключевые метрики для анализа
- Crawl Efficiency (Эффективность сканирования): Отношение количества полезных страниц (целевых посадочных) к общему числу запросов робота. Если бот тратит 50% времени на страницы, закрытые в robots.txt или выдающие 404 ошибку — ваш бюджет расходуется впустую.
- Crawl Depth (Глубина обхода): Насколько глубоко робот заходит в структуру сайта. Если страницы 4-го уровня вложенности и ниже не посещаются месяцами, это явный признак проблем с архитектурой.
- Ratio of Crawled to Indexed: Если количество просканированных страниц значительно превышает количество страниц в индексе, значит, поисковик находит много контента, который считает недостаточно качественным для выдачи (Low Quality Content).
Диагностика позволяет локализовать «дыры», через которые утекают ресурсы краулеров, и подготовить почву для технической оптимизации структуры.
Техническая оптимизация структуры: Наводим порядок в архитектуре
На сайтах с объемом 10 000+ страниц хаотичная структура становится главным врагом индексации. Если робот вынужден преодолевать десятки уровней вложенности, чтобы добраться до карточки товара или статьи, он, скорее всего, прекратит сканирование раньше, чем дойдет до цели.
Правило «3-4 кликов» и вложенность Глубина вложенности (Crawl Depth) — это количество переходов от главной страницы до целевой. Для крупных проектов критически важно, чтобы 95% значимых страниц находились на расстоянии не более 3–4 кликов от главной.
- Плоская структура: Вместо длинных цепочек категорий (Главная > Категория > Подкатегория > Бренд > Модель) используйте более пологие иерархии.
- Пагинация: Для листингов с тысячами товаров используйте численные блоки пагинации, которые позволяют роботу перепрыгивать сразу на 10–20 страниц вперед, вместо последовательного перелистывания «Назад/Вперед».
Оптимизация XML-карт сайта (Sitemap) Sitemap — это не просто список ссылок, а инструмент приоритизации.
- Сегментация: Разделяйте основной Sitemap на несколько файлов (по категориям, по типам контента или по дате обновления). Это поможет быстрее отслеживать в панелях вебмастеров, в каком именно разделе провисает индексация.
- Чистота: В карту сайта должны попадать только страницы с кодом ответа 200 OK, разрешенные к индексации и являющиеся каноническими. Присутствие редиректов или 404 ошибок в Sitemap заставляет робота тратить время на заведомо бесполезные действия.
Управление robots.txt: Фильтрация «шума» Файл robots.txt — это первый файл, который запрашивает бот. На больших сайтах он должен жестко отсекать бесконечные пространства URL-адресов.
- Параметры фильтрации: Закрывайте от индексации страницы сравнения товаров, результаты внутреннего поиска, корзины, личные кабинеты и бесконечные комбинации фильтров, которые не несут поискового спроса.
- Динамические URL: Используйте маски (wildcards), чтобы блокировать мусорные параметры в адресах (например, UTM-метки, сессии, идентификаторы сортировки), которые создают бесконечные дубли одной и той же страницы.
Обработка фасетной навигации Для сайтов с 10 000+ страниц фасетный поиск (фильтры) может генерировать миллионы комбинаций URL.
- Стратегия: Выберите только те комбинации фильтров, которые имеют частотные запросы в семантическом ядре, и сделайте их статичными URL. Все остальные комбинации должны быть закрыты от робота на уровне сервера или через мета-теги Noindex (хотя блокировка в robots.txt экономит бюджет эффективнее).
Правильная архитектура гарантирует, что каждый заход поискового бота будет приносить результат в виде обновления важных страниц, а не блуждания по техническим дебрям.
Борьба с «пожирателями» бюджета: Очистка от технического мусора
На проектах с 10 000+ страниц технический шум может составлять до половины всех запросов поисковых роботов. Когда бот тратит время на сканирование страниц, которые никогда не попадут в индекс или не принесут трафика, он крадет ресурсы у ваших приоритетных товаров и разделов.
Ликвидация дублей страниц Дубликаты — это главная «черная дыра» для бюджета. Если одна и та же страница доступна по пяти разным адресам (например, из-за параметров сортировки или разных категорий), бот просканирует все пять, но в индекс добавит только одну.
- Использование Canonical: Указание канонического адреса помогает боту понять, какую страницу считать основной. Однако помните: rel="canonical" носит рекомендательный характер, и робот все равно может тратить бюджет на обход неканонических копий.
- Физическая склейка: Там, где это возможно, лучше использовать 301-редирект вместо тега Canonical, чтобы физически объединить страницы и направить бота по единственно верному пути.
Обработка цепочек перенаправлений (Redirect Chains) Каждый редирект — это дополнительный запрос. Если для попадания на страницу боту нужно пройти через 2–3 последовательных перенаправления (например, с http на https, а затем с non-www на www), бюджет расходуется в 2–3 раза быстрее.
- Прямые ссылки: Проверьте внутреннюю перелинковку. Все ссылки в меню, футере и теле статей должны вести напрямую на конечный URL с кодом 200 OK, минуя любые редиректы.
Ошибки 404 и «битые» ссылки Когда робот натыкается на «битую» ссылку, он получает негативный сигнал о качестве ресурса. Если таких ссылок тысячи, поисковая система снижает интенсивность сканирования сайта в целом.
- Мониторинг 404: Регулярно выгружайте список 404-ошибок из панелей вебмастеров. Если страница удалена навсегда и не имеет аналога — отдавайте честный код 410 (Gone), это быстрее исключит её из очереди на обход.
- Актуализация линков: Не допускайте ситуации, когда внутренние ссылки ведут на несуществующие разделы.
Удаление малоценного контента (Thin Content) Крупные сайты часто страдают от наличия тысяч страниц с почти пустым содержанием (например, пустые теги, страницы авторов без описания, старые новости).
- Стратегия "Noindex": Если страница нужна пользователю, но не имеет ценности для поиска, закройте её тегом noindex. Это не сэкономит бюджет на первый обход, но в долгосрочной перспективе бот будет заходить на такие страницы значительно реже.
Очистив проект от этого «мусора», вы гарантируете, что каждый запрос робота будет направлен на контент, приносящий конверсии.
Производительность и серверные технологии как ускорители индексации
Скорость работы сервера — это не только фактор ранжирования (Core Web Vitals), но и прямой ограничитель объема сканирования. Если ваш сервер медленно отдает контент, поисковый робот «засыпает» на сайте, успевая обойти лишь малую долю страниц.
Настройка HTTP-заголовков Last-Modified и If-Modified-Since Это один из самых эффективных способов сэкономить до 70% краулингового бюджета на крупных проектах.
- Механика: Заголовок Last-Modified сообщает роботу дату последнего изменения страницы. Когда бот заходит на сайт повторно, он отправляет запрос If-Modified-Since. Если страница не менялась, сервер отдает код 304 Not Modified.
- Результат: Робот не скачивает тело страницы заново, а просто переходит к следующему URL. Это позволяет ему проверить в разы больше страниц за тот же интервал времени.
Внедрение протокола HTTP/2 и HTTP/3 Старые протоколы (HTTP/1.1) открывают отдельное соединение для каждого элемента (картинки, скрипта). Это создает колоссальную нагрузку на сервер при массовом краулинге.
- Мультиплексирование: HTTP/2 и выше позволяют загружать несколько ресурсов через одно соединение. Это критически ускоряет индексацию для Googlebot, который активно поддерживает современные протоколы, снижая нагрузку на процессор вашего сервера.
Сжатие данных и оптимизация ресурсов Чем меньше весит страница (в байтах), тем быстрее бот ее загрузит и тем больше страниц поместится в его дневную квоту.
- Brotli и Gzip: Современные алгоритмы сжатия текстовых данных должны быть настроены на стороне сервера (Nginx/Apache).
- Минимизация кода: Удаление лишних пробелов, комментариев и неиспользуемого JS/CSS кода сокращает объем передаваемого трафика.
Использование CDN и балансировка нагрузки Для сайтов с 10 000+ страниц, имеющих международную аудиторию или распределенную структуру, внедрение Content Delivery Network (CDN) жизненно необходимо.
- Снятие нагрузки: CDN кэширует статические файлы (изображения, стили) на ближайших к роботу серверах. Основной сервер сайта освобождается для обработки динамических запросов поисковика к HTML-коду.
- Стабильность: Балансировщики нагрузки предотвращают падение сайта (ошибки 502, 504) в моменты, когда на сайт одновременно приходят несколько тяжелых краулеров (Google, Яндекс, Bing).
Оптимизация серверной части превращает ваш сайт из «узкого горлышка» в скоростную магистраль для поисковых роботов.
Продвинутая перелинковка для распределения краулингового приоритета
Внутренняя перелинковка на крупных проектах (10 000+ страниц) — это не просто способ передачи веса (Link Juice), но и мощный инструмент управления очередью сканирования. Если робот «живет» на вашем сайте ограниченное время, вы должны подсунуть ему самые важные ссылки в первую очередь.
Иерархическая структура и «силосная» перелинковка (Siloing) Для Enterprise-проектов эффективна стратегия тематической кластеризации.
- Изоляция веса: Ссылки внутри одной крупной категории должны максимально связывать страницы этой же категории. Это создает для робота плотную сеть релевантных URL, удерживая его в рамках целевого раздела и заставляя просканировать его целиком, прежде чем он уйдет на другие ветки.
- Сквозные элементы: Используйте «умные» блоки в футере или боковых панелях, которые динамически меняются в зависимости от раздела, предлагая роботу ссылки на приоритетные подразделы.
Автоматизация перелинковки на больших массивах Когда страниц больше 10 000, ручная простановка ссылок невозможна. Необходимо внедрять алгоритмические блоки:
- Блоки «С этим товаром покупают» или «Похожие статьи»: Они создают дополнительные пути для робота к глубоко вложенным страницам.
- HTML-карты разделов: Для очень глубоких структур полезно создавать вспомогательные текстовые страницы со списками ссылок на подразделы, чтобы сократить путь клика (Click Depth).
- Контекстные ссылки: Автоматическая перелинковка по ключевым словам в тексте помогает роботу находить новые страницы внутри старого, уже проиндексированного контента.
Управление «битыми» и цикличными ссылками На больших сайтах часто возникают скрытые проблемы перелинковки:
- Циклы: Ситуации, когда страница А ссылается на Б, Б на В, а В снова на А. Робот может «зациклиться», тратя бюджет на бесконечный обход одних и тех же URL.
- Скрытые ссылки: Избегайте использования JavaScript для генерации важных навигационных ссылок. Несмотря на то, что Google стал лучше рендерить JS, прямая HTML-ссылка гарантирует 100% обнаружение страницы любым краулером (включая Яндекс) без лишних затрат мощностей.
Приоритизация через анкоры и атрибуты Используйте атрибут rel="nofollow" для ссылок на технические страницы (вход, регистрация, условия использования), если они по какой-то причине не закрыты в robots.txt. Это не всегда экономит бюджет напрямую (бот все равно может увидеть URL), но помогает сфокусировать «внимание» краулера на значимых ссылках.
Грамотная перелинковка превращает разрозненный массив из 10 000 страниц в упорядоченную систему, где каждая важная единица контента находится «под рукой» у поискового робота.
Заключение: Чек-лист регулярного контроля краулингового бюджета
Управление краулинговым бюджетом — это не разовое действие, а непрерывный процесс гигиены крупного сайта. Для ресурсов с 10 000+ страниц любая техническая ошибка масштабируется и может привести к проседанию трафика в кратчайшие сроки. Чтобы ваш проект всегда был в приоритете у поисковых систем, необходимо выстроить систему регулярного мониторинга.
Финальный чек-лист для SEO-специалиста:
- Еженедельный мониторинг логов: Проверяйте, не появились ли аномальные всплески активности роботов на мусорных URL или резкие падения обхода важных разделов.
- Контроль индексации: Сравнивайте количество страниц в файле Sitemap с количеством реально проиндексированных страниц в Google Search Console и Яндекс.Вебмастере. Разрыв более 10–15% — повод для аудита.
- Гигиена кодов ответа: Не допускайте разрастания 404-ошибок. Все удаленные страницы должны либо отдавать 410 код, либо перенаправлять на релевантный аналог через 301-редирект (без цепочек!).
- Проверка robots.txt: Перед любым обновлением структуры сайта проверяйте файл на наличие директив, которые могут случайно заблокировать важные ветки или, наоборот, открыть «мусор».
- Скорость и стабильность: Следите за временем ответа сервера (TTFB). Любое замедление выше 500 мс — это прямой сигнал краулерам сократить активность на вашем сайте.
Будущее краулинга Поисковые системы стремятся к максимальной эффективности. Внедрение таких технологий, как IndexNow (мгновенное уведомление поисковиков об изменениях), позволяет сократить зависимость от традиционного обхода. Однако на текущий момент классическая оптимизация краулингового бюджета остается критически важным навыком для работы с Enterprise-сегментом.
Инвестируя время в чистоту структуры, скорость сервера и качество перелинковки, вы не просто «помогаете» роботу — вы гарантируете своему бизнесу быструю индексацию новых предложений и устойчивое преимущество перед конкурентами в органической выдаче.
Связаться со мной:
Вконтакте: https://vk.com/oparin_art
WhatsApp: 8 (953) 948-23-85
Telegram: https://t.me/pr_oparin
TenChat: https://tenchat.ru/seo-top
Email почта: pr.oparin@yandex.ru
Youtube: https://www.youtube.com/@seo-oparin