Текст подготовил: Андрей Федорчук

Data governance — это цифровая конституция для ваших данных, которая задает правила игры для агентного ИИ. Она отвечает, какие данные агент видит, как он их использует и что никогда не должен отдавать наружу, чтобы бизнес не улетел в штрафы и утечки.
Представьте: маркетинговый агент сам собирает отчеты, пишет письма клиентам и лезет в CRM. Вечером вы видите, что он честно приложил к рассылке файл с сырым финансовым прогнозом по всей компании. Никто не взламывал, просто не было правил.
В 2026 данные — это уже не склад, а топливо, которое постоянно крутится между агентами и моделями. Ниже разберем, что такое data governance простыми словами, как он работает вместе с агентным ИИ и какие 6 шагов нужны, чтобы в РФ это собрать на Make.com без IT-армии.
6 шагов к data governance для агентного ИИ
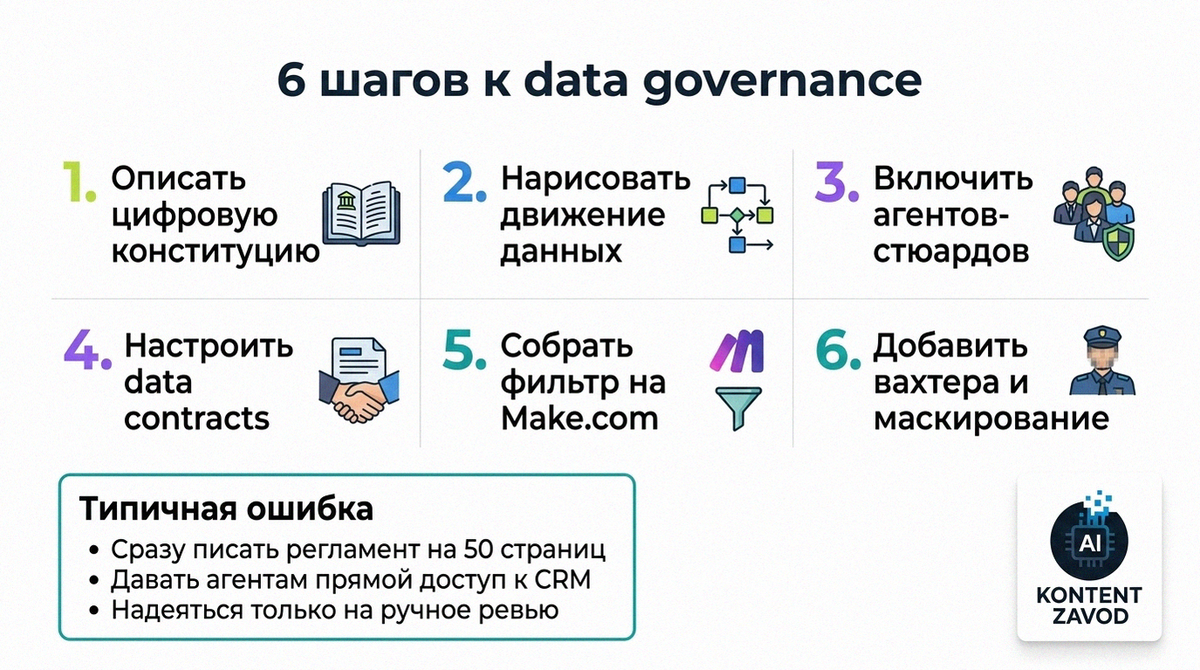
Шаг 1. Опишите свою «цифровую конституцию» на одном листе
Что делаем: фиксируем простыми фразами, какие данные у вас есть (CRM, финансы, поддержка), кто может к ним ходить и что точно под запретом для агентов.
Зачем: без этого любые сценарии на Make.com и агенты будут додумывать сами, а не исполнять ваши правила.
Типичная ошибка: сразу писать регламент на 50 страниц под GDPR и ФЗ-152, который никто не читает и не автоматизирует.
Мини-пример РФ: интернет-магазин в Москве делит данные на три зоны — «Публично» (каталог, отзывы), «Внутри» (продажи, маржа), «Строго» (паспортные данные, чеки). Для каждой зоны отдельные разрешения для агентов.
Шаг 2. Переключитесь с хранения на движение данных
Что делаем: рисуем, как данные бегают между системами — CRM, 1С, телефония, BI, ИИ-агенты. Отмечаем, где именно к потоку подключается агент.
Зачем: data governance 2026 контролирует не только базы, но и маршрут данных между нейросетями и сервисами.
Типичная ошибка: ставить права доступа только на хранилище, а все интеграции пускать сквозняком через вебхуки.
Мини-пример РФ: региональный банк ведет карту движения данных клиента — заявка с сайта, скоринг, колл-центр, внутренний чат-бот. На каждом шаге помечают, что может видеть ИИ-агент и что маскируется.
Шаг 3. Включите автономных стюардов данных
Что делаем: создаем отдельных ИИ-агентов-кураторов, которые следят за качеством и пометками данных, а не продают и не маркетят.
Зачем: роль data steward уходит от ручной в Excel к постоянному мониторингу в реальном времени.
Типичная ошибка: считать, что этим займется админ по совместительству и иногда проверит выборку.
Мини-пример РФ: SaaS-сервис из Казани подключает агента-стюарда, который раз в час проверяет новые строки в БД, ищет странные значения и сам ставит метки «Подозрительно» или «Нельзя в обучение».
Шаг 4. Заведите data contracts между системами и агентами
Что делаем: формализуем «контракты данных» — что именно и на сколько времени может брать агент из CRM, биллинга, хранилища логов.
Зачем: чтобы агент физически не смог сохранить копию чеков или паспортов дольше, чем позволяет политика.
Типичная ошибка: давать доступ по принципу «read-only, там ничего страшного», а потом находить дампы в логах.
Мини-пример РФ: сервис подписок в Санкт-Петербурге описывает контракт для маркетингового агента — он видит город, сегмент, выручку по подписке, но не email и телефон, а кеш запроса живет не дольше 10 минут.
Шаг 5. Соберите эти правила в Make.com как «Фильтр Этичности»
Что делаем: ставим Make.com между агентами и источниками данных, строим сценарий-прослойку с проверкой и очисткой.
Зачем: Make.com превращается в операционную систему data governance, которая не пускает персональные данные дальше, чем нужно.
Типичная ошибка: цеплять агента напрямую к CRM или Notion через API-ключ «на всякий случай» с полным доступом.
Мини-пример РФ: маркетплейс из Екатеринбурга строит сценарий: запрос от агента — Make.com — скрипт проверки на персональные данные — маскирование ФИО в ID — только потом запрос к модели ИИ в облаке.
Шаг 6. Сделайте агента-вахтера и динамическое маскирование
Что делаем: настраиваем отдельного агента-контролера, который проверяет действия других агентов, и включаем автоматическое хэширование и замену реальных данных на псевдонимы по пути.
Зачем: это снижает риск, что один «умный» агент по ошибке сольет лишнее в письмо или отчет.
Типичная ошибка: полагаться только на человеческое ревью писем и отчетов, когда объем уже неуправляем.
Мини-пример РФ: служба поддержки в крупном ритейле — агент готовит ответ клиенту, черновик идет агенту-вахтеру, тот сверяет, что в письме нет паспортных данных и полного номера карты, и только потом Make.com отдает письмо в почтовый сервис.
Сравнение подходов к data governance для ИИ-агентов
Кому data governance с агентами сэкономит время и деньги
Data governance как «цифровая конституция» особенно выгоден там, где агентный ИИ уже лезет в живые данные клиентов и денег.
- Руководителям продуктов и отделов в ecom и финтехе в РФ — чтобы агенты не ломали то, что строили годы.
- CTO и CDO, у кого уже стоят свои модели в контуре (Sovereign AI), но нет понятных протоколов доступа.
- Маркетингу, который хочет использовать агентный ИИ с CRM и транзакциями, не рискуя персональными данными.
- Службам поддержки, где агенты пишут ответы от лица компании и могут случайно раскрыть лишнее.
- Небольшим SaaS и сервисам, которым нужен Zero Trust-подход к данным без найма отдельной команды по безопасности.
Частые вопросы
Data governance — это про юристов или про ИТ?
В 2026 это скорее операционная система для данных. Юристы задают рамки, но исполняют их сценарии, агенты-стюарды и фильтры доступа. Без ИТ и автоматизации цифровая конституция остается бумажкой.
Как data governance связан с агентным ИИ?
Агенты живут на данных. Data governance говорит, какие источники им доступны, что нужно маскировать, какие запросы блокировать и как долго можно хранить результаты. Это защита от утечек и от обучения на мусорных или фейковых данных.
Можно ли обойтись без отдельного агента-вахтера?
Формально да, но тогда вы опираетесь только на настройки каждого отдельного агента и человеческое ревью. Практика показывает, что при росте задач удобнее завести одного «контролера», который проверяет черновики и операции других агентов автоматически.
Как Make.com помогает в data governance?
Make.com работает как прослойка между агентами и системами. Через него можно построить фильтры этичности, динамическое маскирование, реализацию data contracts и логи всех обращений к данным, не трогая сами боевые системы.
Нужны ли синтетические данные малому бизнесу в РФ?
Если вы обучаете своих агентов на истории заказов или обращениях, синтетические данные помогают не светить реальные кейсы клиентов. Это особенно полезно в чувствительных нишах — медицина, финансы, образование.
Достаточно ли держать модели ИИ только в своем контуре?
Суверенный ИИ снижает риск утечки наружу, но не решает проблему избыточного доступа внутри. Если нет Zero Trust и понятных протоколов, агент все равно может забрать лишнее из CRM или бухгалтерии, даже если модель крутится в вашем дата-центре.
С чего начать, если ничего не автоматизировано?
Начните с простого: карта данных и один базовый сценарий-фильтр на Make.com между агентом и самым чувствительным источником. Потом добавляйте агентов-стуаров, контракты данных и метаданные, не пытаясь сделать все сразу.
Какой пункт вашей «цифровой конституции» для данных сейчас самый слабый — доступ, маскирование или контроль агентов? Напишите, и я разберу это в следующих материалах, чтобы не пропустить — подпишитесь на обновления.
#data-governance, #ai-agents, #make-com
AI kontent Zavod:
Связаться с Андреем
Email
Заказать Нейро-Завод
Нейросмех YouTube
Нейроновости ТГ
Нейрозвук ТГ
Нейрохолст ТГ