Введение
Когда-нибудь задумывались, как научить робота приземляться на дроне, не программируя каждый его шаг? Именно это стало целью исследования автора. Он провел недели, создавая игру, в которой виртуальный дрон должен был научиться приземляться на платформу — не следуя заранее подготовленным инструкциям, а изучая методом проб и ошибок, похожим на то, как вы учились кататься на велосипеде.
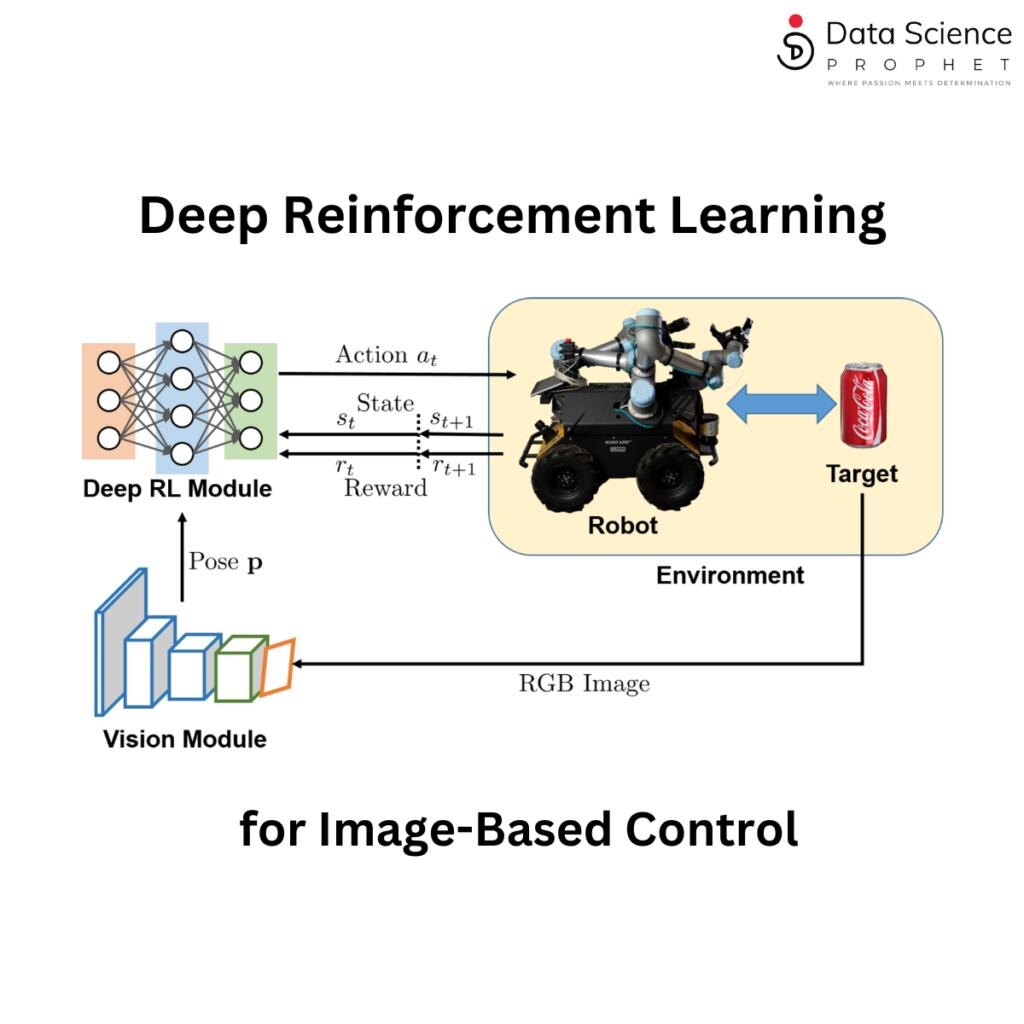
Это и есть обучение с подкреплением (RL), которое кардинально отличается от других подходов машинного обучения. Вместо того чтобы показывать ИИ тысячи примеров "правильных" приземлений, ему дают обратную связь: "Хорошо, но попробуй быть более осторожным в следующий раз" или "Ошибка, ты разбился — не стоит это повторять". Через бесчисленные попытки ИИ понимает, что работает, а что нет.
1. Обзор обучения с подкреплением
Многие идеи можно сопоставить с эксперименами Павлова с собаками и с крысьей клеткой Скиннера. Суть заключается в том, чтобы вознаграждать объект, когда он делает что-то, что вам нужно (положительное подкрепление), и наказывать его, когда он делает что-то плохое (отрицательное подкрепление). Через множество повторений объект учится на этой обратной связи, постепенно открывая, какие действия приводят к успеху — это похоже на то, как крыса Скиннера научилась, какие нажатия на рычаг приводят к получению еды.
Таким образом, мы создаем систему, которая сможет учиться выполнять задачи, чтобы максимизировать вознаграждение и минимизировать наказание.
1.1 Основные понятия
- Агент (или актер): Это наш объект из предыдущего раздела. Это может быть собака, робот, пытающийся ориентироваться на заводе, видеоигровой NPC и так далее.
- Среда (или мир): Это место, симуляция с ограничениями, виртуальный мир видеоигр и т.д. Это можно представить как "коробку", реальную или виртуальную, в которой жизнь агента ограничена; он знает лишь о том, что происходит внутри коробки. Мы, как создатели, можем изменять эту коробку, а агент будет считать, что божество осуществляет свою волю в его мире.
- Политика: Подобно тому, как в правительствах и компаниях "политики" регулируют, какие действия нужно предпринимать в определенных ситуациях.
- Состояние: Это то, что агент "видит" или "знает" о своей текущей ситуации. Это снимок реальности агента в любой момент времени.
- Действие: Теперь, когда наш агент может "видеть" вещи в своей среде, он может захотеть что-то сделать в ответ на текущее состояние.
- Вознаграждение: Каждый раз, когда актер выполняет действие, что-то может измениться в мире.
2. Создание игры
Теперь, когда мы понимаем основы, возникает вопрос: как действительно построить одну из этих систем? Для этой статьи была написана индивидуальная видеоигра, доступная для обучения собственного агенту машинного обучения.
Доставка дрона
Цель игры - управлять дроном (поскольку в нем могут находиться доставки) и приземлиться на платформу. Чтобы выиграть, дрон должен соответствовать следующим критериям:
- Находиться в близости к приземлявшейся платформе
- Двигаться медленно
- Быть в вертикальном положении (приземление вверх дном больше похоже на аварию)
Описание состояния
Дрон наблюдает 15 непрерывных значений, которые полностью описывают его ситуацию над платформой.
3. Проектирование функции вознаграждения
Что делает хорошую функцию вознаграждения? Это, возможно, самая сложная часть RL. Функция вознаграждения — это душа любого RL реализацией. Она должна определять, какое поведение считается "хорошим" и что не должно изучаться. Например, если вы хотите, чтобы дрон приземлялся аккуратно, вам нужно давать положительные награды за близость к платформе и медлительность, при этом наказывая за аварии или расход топлива.
Совет: Чтобы эффективнее измерять вознаграждения, стоит учитывать как положительные, так и отрицательные возможности.
4. Создание нейросетевой политики
Возвращаясь к идее обучения с подкреплением, здесь используется нейронная сеть, которая будет управлять нашим агентом. Ее задача состоит в том, чтобы принимать на вход состояние и вычислять распределение вероятностей для действий, таких как активация главного, левого и правого двигателей дрона.
Заключение
В результате всех этих экспериментов и настроек вознаграждения, автор проекта учил свою модель приземляться, однако осталось много нерешенных проблем, таких как постоянное «зависание» дрона. Это подчеркивает важность вознаграждений, которые должны учитывать изменения состояний, а не только текущее состояние.
В следующих частях будет рассмотрены методы Actor-Critic и как их можно адаптировать для улучшения результатов.
==> Хотите узнать про автоматизации на n8n? — Здесь основные курсы n8n, вы научитесь автоматизировать бизнес-процессы! <==