
🔧 Введение
Последние месяцы я активно работаю с n8n, создавая собственных ИИ-агентов. За это время успел опробовать почти все крупные LLM: GPT, Claude, Gemini, DeepSeek, Grok, Llama и многие другие.
Каждая из них имеет свои плюсы и минусы. Но есть один общий, болезненный недостаток у всех мощных моделей: цена.
💸 Цена топовых моделей — это боль
Если вы работаете с флагманами вроде GPT-4o, Claude Sonnet, Gemini 2.5 Pro или Grok, то цена за 1 млн токенов легко доходит до $10–18. И это при том, что полноценный ИИ-агент с контекстным окном 8–10k токенов, обращением к векторной БД и логикой на стороне n8n, может сжигать по 15–17k токенов за одну генерацию.
А если таких генераций в день — десятки?
Это разорительно. Особенно для энтузиастов и разработчиков без крупных бюджетов.
🔍 В поисках баланса
Я перебрал десятки моделей в поиске идеального баланса между качеством и стоимостью. DeepSeek показался хорошим выбором ($1 за миллион токенов), но… я нашёл ещё более выгодную альтернативу — Qwen3 235B A22B от Alibaba.
💥 Qwen3: 40 раз дешевле, почти без потери качества
Стоимость этой модели — $0.4 за 1 млн токенов. Не на 40%, а в 40 раз дешевле, чем у некоторых флагманов. И, что самое удивительное — по качеству она им практически не уступает.
📊 Сравнение моделей
Qwen3 vs. Gemini 2.5 Pro ($12 за 1M токенов)
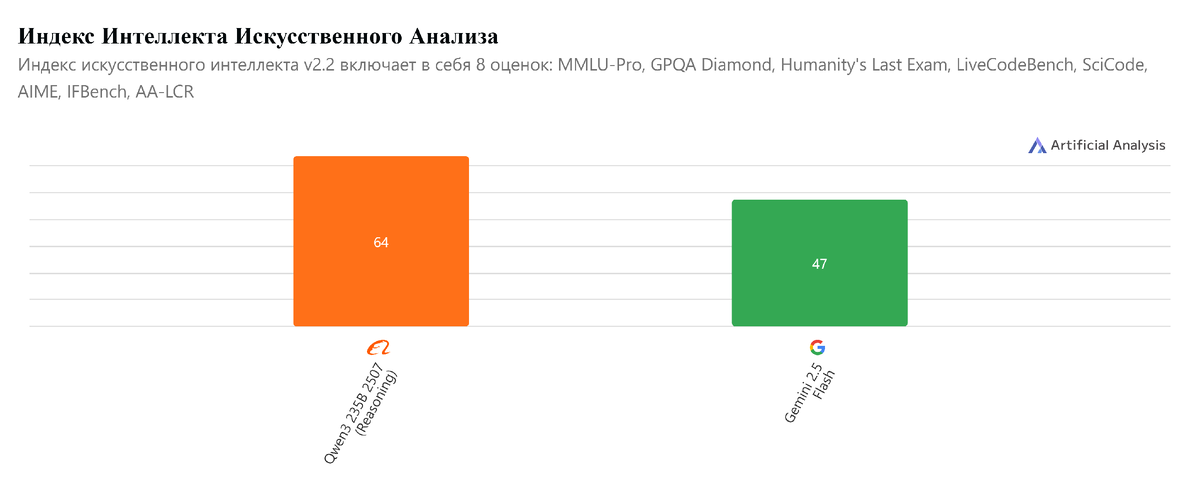
— Qwen уверенно держит сложный системный промпт, не теряет контекст, хорошо соблюдает инструкции.
— Ответы по глубине и логике — на уровне. Разница только в скорости и лёгкой задержке.
Qwen3 vs. Claude Opus:
— По качеству — близко.
— А вот разница в цене почти в 900 раз (!).
✅ Преимущества Qwen3 235B
- Цена
Беспощадно дешёвая. Ни одна модель такого уровня не стоит даже близко так мало. - Качество генераций
Модель уверенно справляется с цепочками, сложными промптами и вложенными структурами. Лучше, чем GPT 4.1 mini или Gemini 2.5 Flash. - Стабильность в n8n
— Работает с таблицами
— Делает запросы в интернет
— Ищет по векторной БД
— Не глючит, не "плывёт" на длинных диалогах
⚠️ Недостатки
— Скорость: генерация занимает чуть больше времени. В среднем, в 2–2.5 раза медленнее, чем у GPT-4o или Gemini.
📉 Почему о ней никто не говорит?
Это удивительно, но Qwen остаётся недооценённой. Вот данные OpenRouter по использованию LLM — Qwen3 там вообще нет:
🔚 Вывод
Если вы создаёте ИИ-агентов в n8n или других low-code системах — обязательно попробуйте Qwen3 235B.
Это идеальная основа для разговорного ИИ, особенно если вы не хотите сливать по $100 в месяц на токены.
Qwen — это случай, когда китайцы сделали что-то действительно не просто дешевле, а лучше за меньшие деньги.