Representational State Transfer — это архитектурный стиль взаимодействия компонентов распределённого приложения в сети. Архитектурный стиль – это набор согласованных ограничений и принципов проектирования, позволяющий добиться определённых свойств системы.
Тяжелое определение с первого раза можно быть не понятно, если говорить попроще, то REST это про то как можно спроектировать систему набор принципов и правил, которое вам помогут сделать
Если мы обратимся опять же к первоисточнику — к работе Филдинга, то мы выясним, что назначение REST в том, чтобы придать проектируемой системе такие свойства как:
- Производительность,
- Масштабируемость,
- Гибкость к изменениям,
- Отказоустойчивость,
- Простота поддержки.
Давно Rest cравнивают с SOAP
SOAP -Обычно, SOAP используется в крупных корпоративных системах со сложной логикой, когда требуются четкие стандарты, подкрепленные временем. XML-RPC, пожалуй, устарел и не имеет смысла ввиду наличия собрата JSON-RPC. RPC-протоколы подойдут для совсем простых систем с малым количеством единиц информации и API-методов.
. Формат данных:
* SOAP: Использует XML для обмена данными, что делает его более сложным и громоздким.
* REST: Более гибкий и может использовать различные форматы, такие как JSON, XML, HTML, plain text и др.
2. Протокол:
* SOAP: Основан на протоколе HTTP, но использует его нестандартным образом, добавляя собственные заголовки и определения.
* REST: Использует стандартные методы HTTP (GET, POST, PUT, DELETE) для взаимодействия с ресурсами.
3. Архитектура:
* SOAP: Опирается на концепцию WSDL (Web Services Description Language) для описания сервиса, что обеспечивает высокую степень формализации и документации.
* REST: Более гибкий и не требует использования WSDL. Описание сервиса обычно осуществляется через документацию или через само приложение.
4. Сложность:
* SOAP: Более сложен в реализации, требует более глубокого понимания XML и WSDL.
* REST: Более прост в разработке, особенно с использованием современных фреймворков.
5. Производительность:
* SOAP: Может быть медленнее, особенно при обработке больших объемов данных, из-за использования XML.
* REST: Обычно быстрее, особенно с использованием легковесных форматов, таких как JSON.
6. Использование:
* SOAP: Чаще используется в корпоративных средах, где требуется высокая степень безопасности и надежности.
* REST: Более популярен в современных веб-приложениях, где важна простота и скорость.
Принцип 1. Клиент-серверная архитектура
Сама концепция клиент-серверной архитектуры заключается в разделении некоторых зон ответственности: в разделении функций клиента и сервера. Что это означает?
Например, мы разделяем нашу систему так, что клиент (допустим, это мобильное приложение) реализует только функциональное взаимодействие с сервером. При этом сервер реализует в себе логику хранения данных, сложные взаимодействия со смежными системами и т.д.
Что мы этим добиваемся и как могло бы быть иначе? Давайте представим, что клиент и сервер у нас объединены. Тогда, если мы говорим о мобильном приложении, каждое мобильное приложение каждого клиента должно было бы быть абсолютно самодостаточной единицей. И тогда, поскольку у нас единого сервера нет для получения/отправки информации, у нас получилась бы какая-то сеть единообразных компонентов – например, мобильные приложения общались бы друг с другом – такая распределённая сеть равноценных узлов.
Такие системы в реальной жизни есть и можно найти их примеры. Например, в блокчейне. Тем не менее, в случае с REST мы говорим о том, что разделяем ответственность. Например, отображение информации, её обработку и хранение.
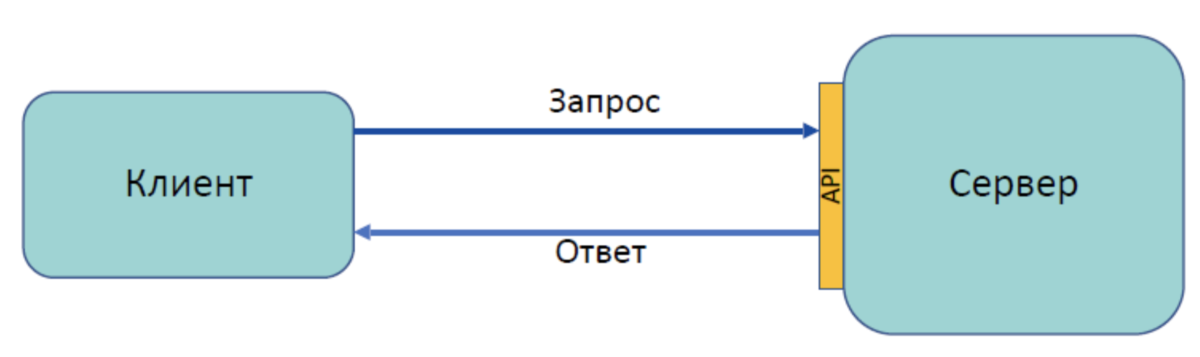
Также сервер может иметь базу данных (см. рисунок ниже). В данном случае надо понимать, что пара «сервер и БД» тоже будет парой «клиент-сервер». Только в данном случае сервером будет БД, а сам сервер — клиентом.

Что дает клиент-серверная архитектура и зачем она нужна?
Во-первых, клиент-серверная архитектура дает нам определённую масштабируемость: есть сервер, есть единая точка обработки запросов. При необходимости выдерживать большую нагрузку мы можем поставить несколько серверов. Также к нему можно подключать достаточно большое количество клиентов (сколько сможет выдержать). Таким образом, клиент-серверная архитектура позволяет добиться масштабируемости.
Во-вторых, REST даёт определённую простоту поддержки. Если мы хотим изменить логику обработки информации на сервере, то выполним эти изменения на сервере. В данном случае мы можем и не менять каждого клиента, как если бы они были абсолютно равноценной сетью.
Конечно, есть и минусы. В случае с клиент-серверной архитектурой мы понимаем, что у нас есть единая точка отказа в виде сервера. Если отказал сервер и у нас нет дополнительных инстансов, то для нас это будет означать неработоспособность системы.
Также потенциально может увеличиться нагрузка, поскольку часть логики мы вынесли с клиента на сервер. Клиент будет совершать меньше каких-либо действий самостоятельно, соответственно, у нас возрастёт количество запросов между клиентом и сервером.
Принцип 2. Stateless
Принцип заключается в том, что сервер не должен хранить у себя информацию о сессии с клиентом. Он должен в каждом запросе получать всю информацию для обработки.
Что это значит?
Представим, что у нас есть некоторый сервис прогноза погоды, в котором уже реализована клиент-серверная архитектура, и мы хотим получить сообщение о прогнозе погоды на завтра.
Что мы делаем в случае, если мы работаем с Stateless? Мы отправляем запрос «Какая погода?», отправляем место, где хотим погоду узнать, и дату. Соответственно, прогноз погоды отвечает нам — «Будет жарко».
Если я захочу узнать, какая будет погода через день, то опять укажу место, где хочу узнать погоду, укажу другую дату. Сервер получит этот запрос, обработает и сообщит мне, что там уже будет очень жарко.
Рассмотрим ситуацию: что было бы, если бы у нас не было Stateless? В таком случае у нас бы был Stateful. В этом случае сервер хранит информацию о предыдущих обращениях клиента, хранит информацию о сессии, какую-то часть контекста взаимодействия с клиентом. А затем может использовать эту информацию при обработке следующих запросов.
Приведём пример на рисунке:
Я всё так же хочу узнать, какая погода будет завтра: отправляю запрос, сервер его обрабатывает, формирует ответ и, помимо того, что он возвращает ответ клиентам, он еще сохраняет какую-то информацию (часть или всю) о том, какой запрос он получил. В случае, если я захочу узнать, какая погода будет через день, я могу сделать такой вызов: «А завтра?». Не сообщая ничего о месте и о дате.
В этом случае у сервера хранится некоторый контекст. Он понимает, что я у него спрашиваю про 21-е число и могу дать ответ на основе информации, хранимой у него в БД или в кэше. Один из примеров, где можно встретить подход Stateful в жизни — это работа с FTP-сервером.
Вернёмся к Statless-подходу. Почему в REST-архитектуре мы должны использовать именно Statless-подход?
Какие он даёт плюсы?
- Масштабируемость сервера,
- Уменьшение времени обработки запроса,
- Простота поддержки,
- Возможность использовать кэширование.
В первую очередь, это масштабирование сервера. Если каждый запрос содержит в себе абсолютно весь контекст, необходимый для обработки, то можно, например, клонировать сервер-обработчик: вместо одного поставить десять таких. Мне будет абсолютно неважно, в какой из этих клонов придёт запрос. Если бы они хранили состояние, то либо должны были синхронизироваться, либо мне нужно было бы умело направлять запрос в нужное место.
Помимо этого, появляется простота поддержки. Каждый раз я вижу в логах, какое сообщение приходило от клиента, какой ответ он получал. Мне не нужно дополнительно узнавать о том, какое состояние хранил сервер.
Также подход Stateless позволяет использовать кэширование.
Какие проблемы может создать Stateless-подход?
- Усложнение логики клиента (именно на стороне клиента нам нужно хранить всю информацию о состоянии, о допустимых действиях, о недопустимых действиях и подобных вещах).
- Увеличение нагрузки на сеть (каждый раз мы передаём всю информацию, весь контекст. Таким образом, больше информации гоняем по сети).
Принцип 3. Кэширование
В оригинале этот принцип говорит нам о том, что каждый ответ сервера должен иметь пометку, можно ли его кэшировать.
Что такое кэширование?
Представим, что у нас всё так же есть сервис по прогнозу погоды, есть клиент, с которым взаимодействуют. Сам по себе этот сервис погоду не определяет. Погоду определяет метеостанция, с которой он связывается с помощью специальных удалённых вызовов. Что происходит, когда мы используем кэширование?
Например, клиент обратился к серверу с запросом «Хочу узнать погоду». Что делает сервер?
Если мы его только запустили и используем кэширование или если мы не используем кэширование вообще — сервер обратится к метеостанции, а она вернёт ему ответ. Перед тем, как сервер ответит клиенту, он должен сохранить эту информацию в кэше. И только потом вернуть ответ. Для чего?
Когда клиент в следующий раз отправит ровно такой же запрос, сервер сможет не обращаться к метеостанции. Он сможет извлечь прогноз из кэша и вернуть ответ клиенту.
Чего мы добились? Мы убрали одну часть взаимодействия между сервером и метеостанцией. Зачем нам это нужно? Это нужно и полезно, если у сервера часто запрашивают одинаковую информацию. Например, кэширование активно используется на новостных сайтах или в соцсетях (на веб-ресурсах, к которым происходит много обращений).
Какие у кэширования плюсы?
- Уменьшение количества сетевых взаимодействий.
- Уменьшение нагрузки на системы (не грузим их дополнительными запросами).
В каких-то случаях одинаковых обращений будет не так много. Тогда кэширование использовать нет смысла.
При этом важно понимать, что кэширование — это совсем не простая штука. Она бывает достаточно сложна и нетривиальна в реализации.
Также мы должны учитывать, что если отдаём какие-то данные, которые сохранили раньше, то важно помнить, что эти данные могли уже устареть.
В каких-то случаях это может быть приемлемо, но в каких-то случаях — абсолютно недопустимо. Соответственно, стоит ли использовать кэширование — всегда нужно обдумывать на конкретном примере.
Принцип 4. Единообразие интерфейса. HATEOAS
Hypermedia as the Engine of Application State (HATEOAS) — одно из ограничений REST, согласно которому сервер возвращает не только ресурс, но и его связи с другими ресурсами и действия, которые можно с ним совершить.
Рассмотрим пример. Возьмём HTTP-запрос, в котором я хочу получить определенный ресурс:
Здесь мы используем HTTP-глагол GET, то есть хотим получить ресурс. Обращаемся к некоторому счёту с номером 12345.
Если бы мы не использовали подход HATEOAS, то получили бы примерно такой XML-ответ:
Здесь указан номер счёта, баланс и валюта.
Что же предлагает HATEOAS? Если бы мы с учётом этого ограничения выполняли бы этот запрос, то в ответе получим не только информацию об этом объекте, но и все те действия, которые мы можем с ним совершить. И, если бы у него были бы какие-то важные связанные объекты, мы получили бы ещё и ссылки на них.
Получая такие ответы, клиент самостоятельно понимает, какие конкретные действия он может совершать над этим объектом и какую ещё информацию о связанных объектах он может получить. Мы даём клиентскому приложению намного больше информации и свободы действий. Логика клиента становится более гибкой, но при этом и более сложной.
Главный плюс этого подхода — клиент становится очень гибким в плане изменений на сервере с точки зрения изменения допустимых действий, изменения модели данных и т.д.
В качестве обратной стороны медали мы получаем сильное усложнение логики, в первую очередь, клиента. Это может потянуть за собой и усложнение логики на сервере, потому что такие ответы нужно правильно формировать. Фактически ответственность за действия, которые совершает клиент, мы передаём на его же сторону. Мы ослабляем контроль валидности совершаемых операций на стороне сервера.
Принцип 5. Layered system (слоистая архитектура)
В предыдущих схемах мы рассматривали сторону клиента и сторону сервера, но не думали, что между ними могут быть посредники.
В реальной жизни между ними могут быть, к примеру, proxy-сервера, роутеры, балансировщики — все, что угодно. И то, по какому пути запрос проходит от клиента до сервера, мы часто не можем знать.
Концепция слоистой архитектуры заключается в том, что ни клиент, ни сервер не должны знать о том, как происходит цепочка вызовов дальше своих прямых соседей.
Знания балансировщика в этой схеме об участниках конкретно этой цепочки вызовов должны заканчиваться proxy-сервером слева и сервером справа. О клиенте он уже ничего не знает.
Если изменяется поведение proxy-сервера (балансировщика, роутера или чего-то ещё), это не должно повлечь изменения для клиентского приложения или для сервера. Помещая их в эту цепочку вызовов, мы не должны замечать никакой разницы. Это позволяет нам изменять общую архитектуру без доработок на стороне клиента или сервера.
Минусы:
- Увеличение нагрузки на сеть (больше участников и больше вызовов, чем если бы мы шли один раз от клиента до сервера напрямую).
- Увеличение времени получения ответа (из-за появления дополнительных участников).
Принцип 6. Code on done (код по требованию)
Идея передачи некоторого исполняемого кода (по сути какой-то программы) от сервера клиенту.
Что это значит?
Представьте, что клиент — это, например, обычный браузер. Клиент отправляет некоторый запрос и ждёт ответа — страницу с определённым интерактивом (например, должен появляться фейерверк в том месте, где пользователь кликает кнопкой мышки). Это всё может быть реализовано на стороне клиента.
Либо клиент, запрашивая данную страницу приветствия, получит в ответ от сервера не просто HTML-код для отображения, а ещё программу, которую он сам и исполнит. Получается, что сервер передаёт исходный код клиенту, а тот его выполняет.
Что мы за счёт этого получаем? Отчасти, это схоже с принципом HATEOAS. Мы позволяем клиенту стать гибче. Если мы захотим изменить цвет фейерверка, то нам не нужно вносить изменений на клиенте — мы можем сделать это на сервере, а затем передавать клиенту. Пример такого языка — javascript.
Насколько же сходятся идеи, которые вложил Рэй Филдинг в концепцию REST, с восприятием REST аналитиками?
Давайте рассмотрим наиболее частые заблуждения, которые вы можете встретить относительно концепции REST.
1. Ограничения REST опциональны (необязательны)
С точки зрения создателя этой концепции существует ровно одно необязательное ограничение — код по требованию. Все остальные ограничения должны выполняться. Если одно из них не выполняется — это уже не REST-подход.
2. REST — протокол передачи данных
REST — это не протокол передачи данных. Он не определяет правила о том, как мы должны передавать запросы, какая у них должна быть структура, что мы должны возвращать в ошибках. Единственное, что косвенно можно было бы приписать — это указание на то, что каждый ответ сервера должен содержать информацию о том, можно ли его кэшировать.
Но, в целом, REST — это концепция, парадигма, но не протокол. В отличие от HTTP, который действительно является протоколом.
3. REST — это всегда HTTP
С одной стороны, ни один из архитектурных принципов REST не говорит нам о том, какой транспорт мы должны использовать — HTTP или очереди.
Но при этом в жизни очень часто встречаются люди, для которых REST и HTTP — это аксиома.
Поэтому, если сказать человеку, что REST — это необязательно HTTP, то вас могут посчитать сумасшедшими.
Почему же все считают, что REST — это HTTP? Здесь нужно сделать ремарку, что одним из главных авторов протокола HTTP — это Рэй Филдинг, автор концепции REST. Рэй Филдинг стремился спроектировать HTTP так, чтобы с помощью него концепцию REST было максимально удобно реализовывать.
4. REST — это обязательно JSON
Почему так сложилось? Главная причина в том, что какое-то время назад сервисы вида JSON over HTTP стали противопоставлять SOAP. JSON одновременно стал популярным и стал антагонистом XML, как SOAP подходу. JSON использовался, потому что это не SOAP.
Модель зрелости REST-сервисов
Ричардсон выделил уровни зрелости REST-сервисов. Выделение происходило исходя из подхода, что REST — это, с точки зрения протокола, всё-таки HTTP. Соответственно, он спроектировал модель, по которой можно понять: насколько сервис REST или не REST.
Уровень 0
В первую очередь, он выделил нулевой уровень. К нему относятся любые сервисы, которые в качестве транспорта используют HTTP и какой-то формат представления данных. Например, когда мы говорим про JSON over HTTP – мы говорим про нулевой уровень.
Если более наглядно «пощупать ручками» с точки зрения использования протокола HTTP, то можно представить, что мы выставляем некоторый API. Мы начинаем с того, что объявляем единый путь для отправки команд и всегда используем один и тот же HTTP-глагол для совершения абсолютно любых действий с любыми объектами. Например: создай вебинар, запиши вебинар, удали вебинар и т.д. То есть мы всегда используем один и тот же URL и всегда используем один и тот же HTTP-метод, обычно POST.
Как один из примеров:
Уровень 1
Следующий уровень — первый. Мы уже научились использовать разные ресурсы и делаем это не по одному URL. Но при этом всё ещё игнорируем HTTP-глаголы.
Мы просто разделяем явно наши объекты, как некоторые ресурсы. Например: спикер, курс, вебинар. Но, независимо от того, что мы хотим сделать — удалить, создать, редактировать, мы всё равно используем один и тот же HTTP-глагол POST.
Уровень 2
Второй уровень — это когда мы начинаем правильно с точки зрения спецификации HTTP-протокола использовать HTTP-глаголы.
Например, если есть спикер, то, чтобы создать спикера и получить информацию о нём, я использую соответствующий глагол: GET, POST. Когда хочу создать или удалить спикера — я использую глаголы: PUT, DELETE.
По сути, второй уровень зрелости — это то, что чаще всего называют REST.
Надо понимать, что, с точки зрения изначальной концепции, если мы дошли до второго уровня зрелости, то это еще не означает, что мы спроектировали REST-систему/ REST-сервис. Но в очень распространённом понимании соответствие 2-ому уровню часто называют RESTfull сервисом.
RESTfull-сервис — это такой сервис, который спроектирован с учётом REST-ограничений. Хотя, в целом, правильнее сервис такого уровня зрелости называть HTTP-сервисом или HTTP-API, нежели REST-API.
Уровень 3
Третий уровень зрелости — это уровень, в котором мы начинаем использовать концепцию HATEOAS. Когда мы передаём информацию, ресурсы, мы сообщаем потребителям (клиентам) о том, какие ещё действия необходимо совершить ресурсу, а также связи с другими ресурсами.
Выводы, которые мы можем сделать из модели зрелости
Итак, как нам эта модель может помочь понять то, что наши коллеги называют RESTом в каждой отдельно взятой компании? REST у вас или не REST?
Первая распространенная трактовка термина REST — всё, что передаётся в виде JSON поверх HTTP.
Вторая, не менее популярная версия, REST — это сервис второго уровня зрелости, то есть HTTP-API, составленное в соответствии со спецификацией HTTP-протокола. Если мы правильно выделяем ресурсы, правильно используем HTTP-глаголы, а также выполняем некоторые требования HTTP-протокола, то у нас REST.
Подведём итоги
Во-первых, у каждого свой REST. Мнения о том, что такое REST, часто разнятся. Когда мы работаем с новыми проектами, новыми коллегами или специалистами, очень важно понять, что именно ваш коллега называет RESTом. Это полезно для того, чтобы на одном из этапов проектирования или разработки не оказалось, что мы половину проекта говорили о разных вещах.
Во-вторых, принципы REST мы часто применяем в жизни. Они очень полезны для осмысления. Кэширование, STATELESS и STATEFUL, клиент-серверная модель или код по требованию — это те вещи, которые аналитику полезно знать для понимания.
Третье — это то, что парадигма REST помогает нам выявить и определить важнейшие свойства архитектуры — масштабируемость, производительность и т.д.