
Естественный поисковой трафик - один из основных каналов привлечения посетителей на сайт и главная задача его продвижения в поисковых системах. В органической выдаче не нужно платить за каждый переход с поиска, а доверие посетителей выше, чем к рекламе. Это делает попадание сайта в зону видимости органической выдачи таким желанным.
Хотя поисковые системы не раскрывают свои алгоритмы, многочисленные исследования и накопленный опыт SEO продвижения позволяют выделить набор внешних и внутренних факторов, анализ и проработка которых с большой вероятностью поможет улучшить позиции сайта в поисковых системах.
Одним из внутренних факторов ранжирования сайта является корректная индексация. Её цель заключается в проверке сайта на наличие ошибок и барьеров, которые мешают поисковым роботам “прочитать” и положить в базу ваш контент. После индексации страницы пройдут еще несколько шагов фильтрации (черновое, чистовое, дополнительное ранжирование), прежде чем попасть в показ результатов поиска. Но именно с обхода сайта краулерами и составлением индекса индексными роботами начинается процесс формирования поисковой выдачи.
Зачем управлять индексацией сайта?
В 1991 году физик Тим-Бернерс Ли запустил первый в истории веб-сайт info.cern.ch. К концу 1992 года их количество выросло до 10. Отметка в 1 миллиард сайтов была впервые достигнута в сентябре 2014 года. По состоянию на июнь 2023 года Всемирная сеть насчитывает 1 106 671 903 веб-сайтов (источник https://siteefy.com/how-many-websites-are-there/).
Роботы поисковых систем не успевают находить и индексировать все существующие URL. Поэтому время, которое отводится на обработку каждого сайта, ограничено. Существует лимит на сканирование (краулинговый бюджет), который определяет, сколько времени и ресурсов краулер может затратить на один сайт. Этот лимит зависит от 2 основных факторов: скорости сканирования и потребности в сканировании. В свою очередь эти показатели зависят от:
- возможностей поисковых систем;
- мощностей сервера;
- размера сайта и периодичности его обновления;
- популярности и качества страниц.
Одним из способов улучшить эффективность сканирования является управление количеством страниц, подлежащих сканированию. Расходуя лимит на сканирование малоценных URL, краулер может замедлить анализ важных страниц или даже посчитать нецелесообразным обрабатывать другие URL. С помощью специальных инструментов можно сообщать роботам, какие страницы следует сканировать, а какие пропустить.
Какие URL рекомендуется закрывать для сканирования:
- Служебные страницы, содержащие техническую информацию или персональные данные.
- Страницы с get-параметрами: идентификаторы сеансов, UTM-метки, поиск, фильтрация, сортировка, сравнение товаров. Создают множество комбинаций URL с дублированным контентом и мета-тегами. Исключение: оптимизированные страницы фильтра с уникальным контентом и мета-тегами.
- Пользовательские страницы: личный кабинет, регистрация, авторизация, корзина, оформление заказа и другие URL с конфиденциальной информацией.
- Страницы с идентичным (дублированным) контентом. Правильным будет отдать роботу уникальный материал и ограничить повторяющийся, сканировать который было бы лишним.
- Страницы с малополезным или спамным контентом.
- Страницы с ошибкой soft 404. Это ошибка, при которой пользователь или поисковая система по URL не получают релевантный контент (страница пустая или визуально оформлена в стиле 404 страницы), а сервер при этом отдает HTTP статус 200. Если страница удалена, нужно отправлять ответ с кодом статуса 404 (not found) или 410 (gone). Если страница перенесена или у нее есть замена, отправляйте ответ с кодом 301 (permanent redirect).
Методы управления индексацией сайта
Существуют различные методы управления поведением роботов поисковых систем в пределах сайта:
- одни направлены на запрет индексации “лишних” страниц;
- другие позволяют оптимизировать процессы сканирования;
- третьи, наоборот, помогают ускорить индексацию сайта.
Файл robots.txt
Robots.txt - служебный файл, который находится в корневом каталоге сайта и содержит набор директив, позволяющих указывать поисковым системам, какие URL (веб-страницы, медиафайлы и ресурсные файлы) должны присутствовать в поиске, а какие - нет.
Когда поисковой робот приходит на сайт, то файл robots.txt является одним из первых документов, к которому он обращается.
В Google и Яндекс robots.txt служит всего лишь рекомендацией для краулера. Даже если файл или директория закрыта, она может попасть в индекс. Чтобы удалить страницу из поиска, следует использовать директиву noindex метатега robots, HTTP-заголовок или сделать страницу доступной только по паролю. При этом не следует ограничивать такие страницы в robots.txt, чтобы роботы могли их проиндексировать и обнаружить указания.
В большинстве случаев robots.txt используется для исключения попадания дубликатов, служебных и других малополезных страниц сайта в индекс поисковых систем. В некоторых случаях к robots.txt прибегают для того, чтобы закрыть сайт от нежелательной поисковой системы и краулеров, не относящихся к поисковым системам (например, AHrefs, SeRanking и т.п.).
При отсутствии файла robots.txt краулеры будут индексировать все встреченные на сайте страницы.
Требования к файлу robots.txt
- Файл должен располагаться строго в корне сайта, называться robots.txt и быть доступен для роботов.
- Файл robots.txt должен быть сохранен в формате plain text в кодировке ASCII или UTF-8.
- Число директив (команд) не должно превышать 1024, а размер файла не должен превышать 500 Кб.
О наполнении и директивах
В файле robots.txt поисковой робот проверяет наличие записей, начинающихся с поля User-agent. Внутри директивы User-agent должна быть хотя бы одна директива Disallow или Allow. Неизвестные директивы игнорируются.
Символ # предназначен для описания комментариев. Всё, что находится после этого символа и до конца строки, не учитывается.
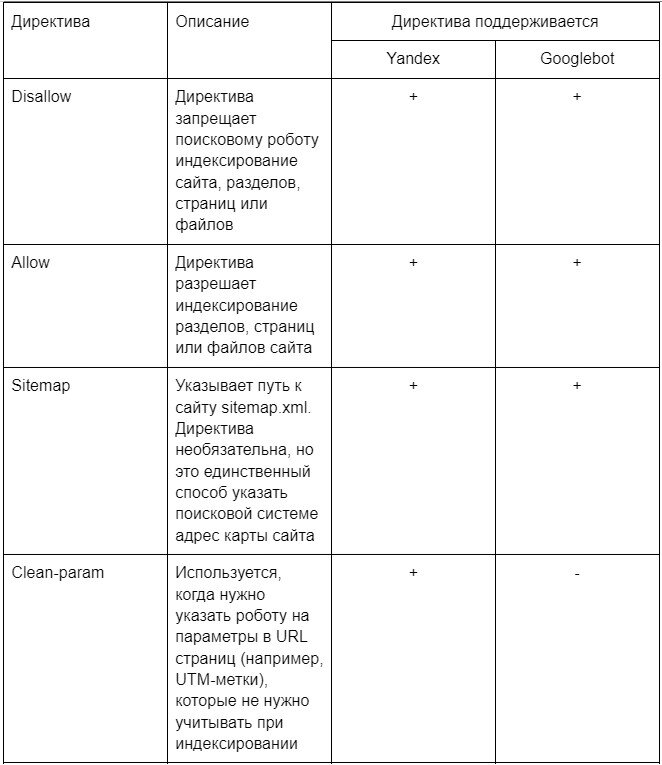
Актуальные директивы robots.txt
Устаревшие директивы robots.txt в Яндексе
Метатеги для индексации сайта
С помощью метатегов можно управлять индексацией сайта, закрывая страницы, ссылки или фрагменты текста.
Метатег robots
В теге <head> каждой страницы можно указать инструкции для роботов поисковых систем по индексированию страницы и показом её фрагмента в результатах поиска. Для этого используется метатег <meta name=”robots” сontent=”...”>.
В отличие от файла robots.txt метатег robots управляет поведением робота при сканировании конкретной страницы, а robots.txt - поведением робота на всём сайте. Например, в метатеге можно указать, чтобы робот не ходил по ссылкам на странице, а в robots.txt такая возможность отсутствует.
Чтобы обнаружить метатеги robots, краулер должен просканировать страницу. Поэтому не следует закрывать такие страницы от индексации в robots.txt, чтобы роботы могли увидеть указания. В противном случае правила метатега будут проигнорированы.
Тенденция: в последнее время SEO-оптимизаторы фиксируют случаи, когда поисковые системы Яндекс и Google игнорируют директивы Disallow и <meta name="robots" content="noindex"/>, показывая страницы в результатах поиска.
Как и в файле robots.txt, эти инструкции могут быть общими:
<meta name=”robots” content=”noindex” />
Или специфические для конкретного бота:
<meta name=”googlebot” content=”noindex” />
Виды директив метатега robots
Можно указывать несколько правил метатега robots, перечислив их через запятую:
<meta name="robots" content="noindex, nofollow">
или использовать каждое правило отдельно:
<meta name="robots" content="noindex">
<meta name="robots" content="nofollow">
Роботы Яндекс и Google по-разному интерпретируют директивы с противоречиями. Робот Яндекса учтет положительное значение:
<meta name="robots" content="all"/>
<meta name="robots" content="noindex, follow"/>
<!--Робот выберет значение all, текст и ссылки будут проиндексированы.-->
А Google применит наиболее строгое из них:
<meta name="robots" content="max-snippet:50"/>
<meta name="robots" content="nosnippet"/>
<!--Робот использует вариант nosnippet-->
Перечисленные ниже элементы являются запрещающими и задаются на уровне текста в HTML в коде конкретной страницы.
Атрибут rel=”nofollow”
Использование этого элемента позволяет запрещать поисковым роботам переходить по определенным ссылкам на странице. Атрибут rel=”nofollow” в первую очередь используется, чтобы указать краулеру приоритеты при сканировании сайта. Запрещая переходить на малополезные страницы, он экономит краулинговый бюджет и время индексации.
Атрибут указывается в теге <a> в коде страницы. Например,
<a href=”/catalog/example/” rel=”nofollow”>пример</a>
Проверить, к каким ссылкам добавлен атрибут, можно с помощью плагина RDS Bar.
Атрибут data-nosnippet
Этот HTML-атрибут используется для разметки фрагментов текста на странице, которые не следует показывать в результатах поиска. Поддерживается только Google.
Атрибут data-nosnippet может указываться без значения в HTML-элементах span, div и section. Например,
<p>Этот текст можно показывать в сниппете <span data-nosnippet>а этот фрагмент отображать нельзя</span>.</p>
<div data-nosnippet>не показывать в сниппете</div>
Метатег <!--noindex--> / <noindex>
Предназначен для запрета от индексации элементов на странице. Это могут быть как части кода, так и дубли контента.
Метатег <noindex> воспринимается только поисковой системой Яндекс, Google данный тег не поддерживает.
В текущих реалиях тег <!--noindex--> практически не используется на практике, т.к. бесполезен в качестве защиты от переспама. А в худшем может стать сигналом для Яндекса, что на сайте есть нарушения (пруфы).
Определить наличие закрытых на странице элементов можно также с помощью плагина RDS Bar.
HTTP заголовки
Протокол HTTP - это язык, на котором “разговаривают” с помощью запросов и откликов клиент (например, браузер или поисковой робот) и веб-сервер сайта. При каждом запросе к серверу браузер или робот передает служебную информацию в HTTP-заголовках. Например, типы передаваемых и поддерживаемых браузером данных, адрес ссылающейся страницы, с которой перешел посетитель и т.д. Некорректная обработка кодов ответа может привести к проблемам с ранжированием, вплоть до исключения страниц из поисковой выдачи.
Код ответа 200 ОК сигнализирует поисковой системе о том, что страницу можно индексировать и показывать в результатах поиска.
Редиректы 301/302 используются при смене URL и указывают, что сайт или конкретная страница переехали с одного адреса на другой.
При обращении к несуществующей странице сервер должен отдавать код 404 (HTTP 404 Not Found). Некорректная обработка запросов к несуществующим страницам может привести к неправильной индексации сайта, появлению большого количества дублей и мусорных страниц в индексах поисковых систем.
Помимо вышеперечисленных существуют код ответа сервера 304 и HTTP-заголовок X-Robots-Tag, которые позволяют управлять индексацией сайта. Расскажем о них подробнее.
HTTP-заголовок X-Robots-Tag
Помимо метатега robots существует еще один способ указать роботам правила загрузки и индексирования конкретных страниц сайта. Это HTTP-заголовок X-Robots-Tag.
Если метатег robots прописывается в HTML-коде страницы в элементе <head>
<html>
<head>
<meta name="robots" content="noindex" />
</head>
<body>...</body>
</html>
то заголовок X-Robots-Tag в HTTP ответе сервера для определенного URL.
HTTP/1.1 200 OK
Date: Tue, 20 September 2023 19:32:04 GMT
X-Robots-Tag: noindex
Как и для файла robots.txt и тега robots, в заголовке X-Robots-Tag можно указать директивы для определенных роботов. Но если Google поддерживает все те же правила, что и для метатега robots, то Яндекс сможет обработать через заголовок X-Robots-Tag только 4 директивы - noindex, nofollow, none, noarchive.
Как и в случае с метатегом robots краулеры Яндекс и Google по-разному интерпретируют директивы заголовка X-Robots-Tag с противоречиями (см. метатег robots).
Метатег robots и HTTP-заголовок X-Robots-Tag похожи по функционалу и поддерживаемым директивам. Но для интерпретации HTTP-заголовков роботу не нужно анализировать контент страницы целиком, т.к. правила задаются на уровне HTTP-ответа. Получая Noindex через XRT, робот не обрабатывает страницу. Кроме того метатег robots работает только с HTML форматом файлом. Для запрета индексации документов pdf, видео или изображений в таком случае подойдет X-Robots-Tag. В этом заключается его преимущество перед meta robots.
HTTP-заголовки Last-Modified и If-Modified-Since
Чем чаще на сайте изменяется информация и добавляются новые страницы, тем чаще на него будет приходить робот поисковой системы. При посещении страницы краулер должен понять, изменилась она с момента последнего визита или нет. Для этого он скачивает страницу к себе в базу и сравнивает с предыдущей версией. Если страница содержит значимые изменения, то её копия в индексе заменяется новой, если нет, то в индексе остаётся вариант, скачанный ранее. В итоге может сложиться ситуация, когда краулер расходует краулинговый бюджет на неизменившиеся страницы, а на новые у него не хватает ресурсов. Кроме того сайты с большим количеством страниц могут столкнуться с еще одной проблемой: неоправданной нагрузкой на сервер при скачивании поисковым робот “лишних” страниц.
Данная ситуация решается настройкой на сервере заголовков Last-Modified и If-Modified-Since. Эти HTTP-заголовки сообщают поисковому роботу, изменилась ли страница с момента его последнего посещения. Если нет, робот получит от сервера ответ 304 Not Modifed (документ не изменялся) и саму страницу не отдаст. Тогда краулер оставит в индексе старую копию документа и сможет уделить больше внимания новым страницам и страницам с изменениями.
Пример корректной обработки HTTP-заголовков Last-Modified и If-Modified-Since:
Проверить настройку HTTP-заголовков Last-Modified и If-Modified-Since на своем сайте можно тут https://last-modified.com/.
Корректная обработка запросов с датами изменений документов актуальна для сайтов с большим количеством страниц. Это ускорит сканирование сайта поисковыми роботами за счет рационального расходования краулингового бюджета на новые или обновленные документы.
Канонические ссылки
Для управления каноническими адресами страниц сайта используется атрибут rel="canonical". Если на сайте есть страницы со схожим контентом, то с помощью rel="canonical" можно указать поисковому роботу, какая версия страницы должна отображаться в результатах поиска.
Директива не является строгой и может быть проигнорирована поисковыми системами. Но исходя из нашего опыта, вероятность корректной обработки повышается, если контент страниц совпадает полностью.
В каких случаях стоит указать канонический адрес страницы:
- Если нужно указать поисковому роботу, какой url должен присутствовать в результатах поиска.
- Для управления дублированным контентом. Canonical поможет поисковым системам связать материалы, задать самый высокий рейтинг для исходной страницы и оптимизировать затраты на сканирование повторяющихся страниц.
Директиву rel=”canonical” можно добавить двумя способами:
- внедрить элемент link с атрибутом rel=”canonical” на HTML-страницу в разделе <head>.
- указать атрибут rel=”canonical” в HTTP-заголовке link.
Можно использовать оба способа для большей надежности.
Если вы не укажите канонический URL, то поисковая система сама определит, какая страница или версия URL является наиболее подходящим вариантом для размещения в результатах поиска.
Что еще важно знать о канонических ссылках:
- Элементы link с атрибутом rel=”canonical” должны содержать абсолютные пути, а не относительные.
- URL, который указывается в rel=”canonical”, должен вести на существующую страницу (200 ОК). Канонические ссылки на несуществующие страницы снижают эффективность сканирования и индексирования и нерационально расходуют краулинговый бюджет.
- Для Яндекса директива является внутрихостовой (обрабатывает ссылки только внутри сайта).
Google поддерживал кроссдоменные директивы canonical. Но в 2023 году в документацию были внесены изменения. Если раньше Google рекомендовал использовать rel=canonical для управления скопированным контентом, размещенном на других доменах, то сейчас наиболее эффективным решением является установка запрета на индексирование вашего контента на сайтах партнеров. Поэтому скорее всего можно говорить о том, что Google перестал обрабатывать ссылки из разных доменных зон.
Как ускорить индексирование сайта
В Яндекс и Google существует несколько инструментов, помогающих ускорить индексацию или переиндексацию сайта. С их помощью можно сообщить индексирующему роботу об изменениях на сайте (новых, удаленных или изменившихся страницах), чтобы они быстрее отразились в результатах поиска.
Файл Sitemap
Sitemap (XML-карта сайта) - документ с URL-адресами и метаданными, который сообщает поисковым системам о страницах, доступных для индексации. Если файл robots.txt в основном используется для запрета индексации, то sitemap.xml отвечает за ускорение и полноту индексации сайта.
Файл Sitemap должен автоматически обновляться при добавлении / удалении страниц с сайта и включать в себя ссылки только на важные и доступные для роботов страницы сайта, содержащие уникальный контент. Использование метаданных, связанные с конкретным URL, позволит оптимизировать процесс индексации и переиндексации через xml-файл:
- <lastmod> - дата последнего обновления страницы;
- <changefreq> - частота изменения страницы;
- <priority> - приоритетность страницы в рамках сайта, указываются значения коэффициента от 0.0 до 1.0.
Не забудьте добавить ссылку на файл sitemap в панели Вебмастеров и robots.txt, чтобы роботы Яндекс и Google быстрее его увидели.
Инструмент “Переобход” в Я.Вебмастер
Сообщить Яндекс о новых или измененных страницах можно в панели Вебмастера через инструмент “Переобход страниц” в разделе “Индексирование”.
Достаточно указать в поле адреса страниц и нажать кнопку “Отправить”. Робот посетит указанные URL в приоритетном порядке при следующем обращении к сайту.
Инструмент “Проверка URL” в Google Search Console
Чтобы сообщить о новой или обновленной странице поисковой системе Google, воспользуйтесь инструментом проверки URL в панели GSC.
Если страницы нет в индексе, запросите сканирование страницы роботом Googlebot.
Если страница присутствует в индексе Google, то её можно отправить на переиндексацию:
Яндекс IndexNow и Google Indexing API
Протоколы IndexNow и Indexing API позволяют сообщать Яндекс и Google об изменениях на сайте, не дожидаясь планового обхода индексирующими роботами.
Возможности Яндекс IndexNow и Google Indexing API:
- Обновление URL. Сообщайте роботам о новых или измененных страницах.
- Отправка пакетных запросов индексирования. Лучший способ, когда требуется отправить на индексирование большое количество URL.
- Google: в одном HTTP-запросе можно объединить до 100 адресов. По умолчанию квоты для проекта зависят от типа запроса и качества документа. Узнать свою квоту можно в Google API Console. Также можно подать запрос на увеличение квоты.
- Яндекс: в одном запросе можно передавать до 10 000 адресов. Ограничений на количество запросов нет, но Яндекс использует алгоритмы, ограничивающие слишком большой поток запросов.
- Удаление URL из индекса. Сообщите поисковой системе об удаленной странице, чтобы краулер не пытался повторно просканировать этот URL.
- Получение статуса запроса. Узнайте, когда поисковой робот в последний раз получал уведомления для конкретного URL.
Подключение протоколов и работа с ними требуют определенных знаний и навыков. Если ваш сайт небольшой, то вполне можно обойтись стандартными инструментами Я.Вебмастер и Google Search Console.
Узнать больше о работе протоколов и ознакомиться с инструкциями по подключению:
Как удалить страницы из поиска
Иногда в практике возникают случаи, когда из результатов поиска нужно убрать страницу или группу страниц сайта. Для этого необходимо установить запрет на индексирование страницы.
Если страница удалена с сайта
- Закройте от индексации страницу или каталог директивой Disallow в файле robots.txt.
→ Рекомендуется использовать, если нужно удалить из поиска Яндекса множество страниц. Последовательный обход роботом может занять некоторое время, а к файлу robots.txt при обходе краулер обращается в первую очередь.
- Настройте HTTP-ответ сервера с кодом 404 Not Found, 403 Forbidden или 410 Gone.
Для удобства пользователей и SEO-оптимизации для некоторых удаленных страниц рекомендуется настраивать 301 редирект на релевантные страницы или основные страницы каталога:
- Пользователь попадает не на удаленную страницу, а на близкую к ней по релевантности.
- Вес с такой страницы перейдет на другую страницу сайта, а не исчезнет просто так.
Если страница не должна отображаться в поиске
- Используйте на странице метатег robots или HTTP-заголовок X-Robots-Tag с директивой noindex.
→ Не ограничивайте такую страницу в robots.txt, чтобы робот смог её просканировать и обнаружить указания.
- Настройте HTTP-ответ сервера с кодом 404 Not Found, 403 Forbidden или 410 Gone.
- Заблокируйте доступ к контенту, установив пароль.
Самым надежным из всех перечисленных способов является удаление страницы. А менее безопасным директива noindex в meta robots или XRT.
Как ускорить удаление страницы из поиска в Яндексе
В панели Я.Вебмастер есть инструмент “Удаление страниц из поиска”, который позволяет внепланово (не дожидаясь планового обхода робота) сообщить Яндексу о необходимости удаления страницы из поиска.
Для URL должен быть установлен запрет на индексирование или он должен отдавать ответ сервера 404 Not Found, 403 Forbidden или 410 Gone. В других случаях заявка на удаление страниц из поиска будет отклонена.
Удалить можно как отдельные страницы из поиска (по URL):
Так и группы страницы (по префиксу):
Как быстро заблокировать показ URL в поиске Google
Чтобы быстро (в течение одного дня) исключить страницу из результатов поиска Google, воспользуйтесь инструментом удаления URL в панели Google Search Console.
Инструмент позволяет временно исключить страницы из результатов поиска, но не удалить их навсегда. Чтобы удалить контент из Google Поиска навсегда, воспользуйтесь один из трех способов, перечисленных выше.
Важно:
- Страницы блокируются на срок до 6 месяцев.
- Блокировка URL не запрещает роботу Google сканировать страницу, а только препятствует ее показу в результатах поиска.
- Страница, отправленная на временную блокировку, должна быть доступна для робота. Страницы с кодами ответа 404, 502 или 503 Google причислит к удаленным, а запрос на блокировку утратит силу.
Источники
- DrMax. SEO Монстр 2020. Руководство по глобальному продвижению сайтов и интернет-магазинов.
- DrMax. SEO Монстр Next. Том 2. Технические вопросы продвижения и аудита сайтов. – 2023.
- Ашманов И. Оптимизация и продвижение в поисковых системах/ И. Ашманов [и др.]. – 4-е издание. – СПб: Питер, 2019. – 512 с.
- Индексирование сайта. Яндекс Справка [Электронный ресурс]. – Режим доступа: https://yandex.ru/support/webmaster/index.html.
- Сканирование и индексирование. Документация Центра поиска Google [Электронный ресурс]. – Режим доступа: https://developers.google.com/search/docs/crawling-indexing?hl=ru.
- Телеграм-канал SEalytics (Сергей Людкевич) [Электронный ресурс]. - Режим доступа: https://t.me/sealytics.




















