Введение
В настоящее время в системе здравоохранения закрепился принцип доказательной медицины, позволяющий путем исследований выявить особенности заболеваний и эффективные способы их лечения. Вместе с тем существуют проблемы данного принципа и его слабые места. Одной из них является большое время и трудозатратность проведения исследований, что влечет ряд компромиссов в виде уменьшения выборки, увеличения финансирования, проведения исследований силами специальных исследовательских лечебных заведений и др. Решение этих трудностей – лишь один из путей повышения полноты и достоверности знаний об эффективности лечения.
Другой путь, дополняющий оптимизацию медико-биологических исследований – первичный статистический анализ и использование данных, которые по тем или иным причинам не исследуются. Такими данными являются физиологические показатели пациентов, параметры симптомов новых или редких заболеваний, данные лечения сочетаний заболеваний. Своевременные обработка и использование результатов анализа этих данных должно помочь принимать решения в процессе работы как отдельного врача или больницы, так и системы здравоохранения в целом, указывая упущенные из внимания особенности и закономерности болезней и их лечения.
1. Цель работы
Цель работы состоит в использовании методов распознавания в задачах автоматизированного определения лекарственных препаратов на основе данных пациента. Для достижения цели требуется изучить:
- графические нотации проектирования процессов;
- структуру описания пользовательских программ и виды тестирования программных продуктов;
а также практически выполнить:
- идентифицировать требования к процессам обучения и тестирования классификатора по предложению лекарственных средств;
- спроектировать процессы в IDEF0 и IDEF3 для моделей AS-IS и TO-BE до 3-4 уровней детализации;
- реализовать и количественно оценить программное приложение для автоматизации работы больницы в среде Python.
Объектом текущего исследования является проблема использования ИТ/ИС в медучреждениях, предметом исследования – работа врача по подбору лекарственного препарата по данным пациентов. Практическая ценность исследования заключается в описании проблемы и опыта ее решения с использованием исследуемых математических методов в процессе разработки информационной системы.
2. Анализ методов распознавания образов
Методы распознавания образов – математический аппарат, предназначенный для классификации и верификации объектов реального мира из выборки по их параметрам. Класс – это множество объектов с общими свойствами (параметрами), существенными для решения конкретной задачи над объектами предметной области. При этом, объектам класса дается метка класса. Например, в гражданской авиации для приема пассажиров терминалом аэропорта требуется знать тип самолета, классифицировав его по размеру, требуемому трапу, набору оборудования, к обслуживанию которого надо быть готовым техническому персоналу.
Классификация – процесс причисления объекта к какому-либо классу по его параметрам (приписывание метки класса). Верификация – сопоставление объекта с описанием (моделью) класса. Объектами класса могут служить как отдельные объекты, которые можно сосчитать, так и дискретные отсчеты непрерывной величины (например, двумерного изображения, дробящегося на пиксели для их классификации). В любом случае, классифицируемый объект представляется вектором y = (x0, x1, … , xN-1), где x – значение признака, а N – количество признаков (N-мерное пространство). Признак может быть любым значением: числом, значением алфавита формального языка, матрицей или иным объектом.
В задачах классификации большую роль играет сама выборка. Во-первых, она должна быть репрезентативна: количество ее членов должно быть достаточно большим, чтобы ее свойства не отличались от свойств генеральной совокупности. Во-вторых, позиция элемента в выборке может быть одним из параметров объекта. То есть, пусть у нас есть выборка из элементов y0, y1, … yn, тогда yi = (i, x x1, x2, …, xN), где x ∈ (0;N-1).
Рассмотрим метод ближайшего соседа. Метод является метрическим и причисляет элемент выборки к классу, к которому принадлежит ближайший к нему элемент. Мера близости – величина, вычисляемая из параметров классифицируемого объекта и параметров классифицированных объектов выборки:
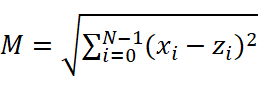
здесь M – мера расстояния, xi – параметр классифицируемого объекта, zi – параметр ранее классифицированного объекта, N – размерность пространства признаков (их количество).
Если была найдена минимальная M, тогда определяется, к какому классу принадлежит z и x причисляется к этому же классу. Мера ищется разными способами. Примененный нами вариант описан в разделе разработки и тестирования. Этот метод неустойчив к шумовым выбросам и наиболее применим в случае многотонного изменения признака. Для купирования этого недостатка разработаны его дополнения. Без дополнений возникает необходимость ручного отсеивания данных выборки исходя из предположения, что параметры классифицируемого объекта изменяются монотонно и делят пространство параметров на отчетливые области [1].
Полный текст статьи: https://corpinfosys.ru/archive/issue-14/126-2021-14-recognition
