Ключевые моменты:
- нейронные сети становятся все более распространены, активно внедряются решения на их основе;
- существует дефицит производительных решений для корпоративного сегмента;
- ComBox NUC Server на базе Intel NUC8i5BEK – высокопроизводительное и экономически эффективное решение для корпоративного сегмента.
Мир меняется очень быстро, и недавние идеи фантастов сегодня стали реальностью. Искусственный интеллект, нейронные сети, машинное обучение, машинное творчество - если еще пять лет назад подобные фразы привлекали к себе повышенное внимание, то в современном мире эти понятия уже плотно вошли в обиход.
Сферы применения искусственного интеллекта активно расширяются. Ритейл, логистика, транспорт, банковская, производственная сфера, электроэнергетика, ВПК… Можно продолжать долго, ведь инновации коснулись практически каждой отрасли.
Количество идей и готовых решений на базе нейронных сетей стремительно растет. Корпоративный сегмент готов внедрять инновации и заинтересован в высокопроизводительных устройствах, которые позволят раскрыть весь потенциал предлагаемых решений. И сталкивается с проблемой практически полного отсутствия специализированных решений в корпоративном сегменте, хотя именно он в настоящее время является наиболее растущим.
Обучение, деплой, инференс
Есть множество различных топологий нейронных сетей, которые выбираются в зависимости от решаемой задачи.
Обычно нейронная сеть проходит три жизненных этапа: обучение, деплой и инференс.
Для обучения сначала формулируется задача. Например, мы хотим распознавать кроликов на дороге и считать их количество. Значит, нам нужен детектор и счетчик кроликов. Для этого нужно получить обучающую выборку - видеопоток с дороги, где бегают кролики, порезать его на кадры и разметить, т.е. выделить кролика на изображении. После этого запускают процесс обучения нейронной сети по обучающей выборке. Этот процесс выгодно делать на GPU (видеокартах), поскольку в каждой видеокарте есть специализированные тензорные ядра и множество векторных арифметическо-логических устройств (ВАЛУ). Можно обучать нейросеть и на CPU, но это потребует на порядок больше времени. В CPU, в среднем, от 2 до 32 ядер в каждом. А в самом недорогом GPU уже 2000 ВАЛУ (ядер, в случае обучения).
Сети учатся эпохами, т.е. обучающая выборка повторяется несколько раз и каждый раз уточняются весовые коэффициенты. Результатом мы получаем набор весовых коэффициентов, которые сворачиваются в случае использования сверточных нейроных сетей (СНН). У сети есть набор слоев, которые выполняются последовательно. Сама блок-схема выглядит вот так:
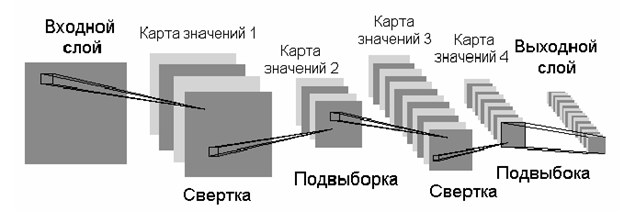
После обучения выполняется деплой - выкладывание сети. Это процесс. Когда сеть выложена (человеком, установщикам или с применением средств автоматизации), то начинается инференс: на вход приходят живые данные, которые преобразуются в выходные предварительно обученной нейронной сетью.
Инференсом называется непрерывная работа какой-либо нейронной сети на конечном устройстве. Инференс выполняется для совершенно разных нейронных сетей, например, для нейросетей по распознаванию марок, моделей транспортных средств, лиц, голосов, анализа текстовых материалов и много другого. То есть, это процесс исполнения сети, когда она уже готова к проведению полезной работы.
Особенности инференса
В настоящее время для инференса нейронных сетей используются процессоры общего назначения CPU, графические процессоры GPU, специализированные FPGA (field programmable gate array).
В случае использования CPU, инференс выполняется на логических ядрах процессора, число которых равно числу физических ядер или, при использовании технологии Hyper-threading, увеличено вдвое. Решения на современных многоядерных процессорах достаточно дороги, а использование CPU на больших (глубоких) нейросетях неэффективно из-за ограниченного объема кэша процессора и необходимости организации обмена данными с ОЗУ, что существенно влияет на скорость работы. Кроме того, ограничения на производительность накладываются самой архитектурой - в процессе инференса решаются простые задачи сравнения, которые легко переносятся на параллельные вычисления, но количество параллельных потоков обработки всегда будет ограничено количеством логических ядер CPU. Сервера выполняются в форм-факторе U для возможности размещения в стойках RACK центров обработки данных.
Инференс с использованием GPU за счет иной архитектуры процессора, наличия высокоскоростной памяти и гибкой системы управления кэш-памятью гораздо более эффективен, чем инференс на CPU. Плюсом является кардинальное (до 100 раз) ускорение работы и крайне высокая эффективность обучения нейросети по сравнению с CPU. Одним из основных недостатков этого типа серверов является высокая стоимость решений, которая складывается из цены видеокарт и общей обвязки. В результате итоговая стоимость решения может достигать $20 000. Второй недостаток - необходимость адаптации существующих сетей различных топологий для использования GPU. Третий, и тоже немаловажный, - это узкий круг применения данных решений в отличие от серверов, построенных на процессорах общего назначения. GPU сервера также выполняются в форм-факторе U для использования в существующей инфраструктуре ЦОД.
Инновационным подходом явилось использование FPGA применительно к нейронным сетям. FPGA представляет собой сеть из миллионов программируемых блоков, которые можно программно соединять между собой, а нейросеть хранить непосредственно внутри FPGA. Такие особенности архитектуры снижают потребность в быстрой передаче данных и позволяют добиться крайне высокой производительности при более низких тактовых частотах и, как следствие, – кардинально снизить энергопотребление. Основная проблема для широкого применения FPGA заключается в низкой эффективности решения при обучении нейросети, сложности программирования и ограниченном количестве специалистов на рынке.
Эффективность инференса
Как понять, инференс на каких устройствах наиболее эффективен? Нужно сравнить эффективность на разных устройствах. Но по каким параметрам сравнивать? Предпринимались разные попытки сравнить производительность устройств при инференсе, но объективность сравнений, мягко говоря, хромала. Пытались сравнить количество логических ядер разных устройств, заявляя, что количество ядер имеет решающее значение, пытались сравнить количество потоков.
Мы попытались привязать эффективность к стоимости. Было проведено большое исследование скорости сетей различных топологий на различных видах устройств (процессоры и видеокарты) с привязкой к стоимости. С ним можно ознакомиться по ссылке - https://tinyurl.com/y2thwjs6 . Основные метрики, которые нас интересовали - это цена за FPS (frame per second) и скорость (relative FPS).
Получились интересные результаты, на основании можно сделать вывод, что максимальную скорость инференса при оптимальной стоимости FPS можно получить на Intel NUC8i5BEK. Intel NUC - это SBC, одноплатный компьютер. Одноплатных компьютеров много (небольшой их список приведен здесь - https://tinyurl.com/yxo9ylrj) , но именно NUC8i5BEK показывает лучшие результаты.
Инференс на одноплатных компьютерах, и NUC'ах в том числе, реализуют, но это сложно назвать корпоративным решением. Их сложно установить в ЦОД, потому что для установки потребуются полки, ведь SBC нужно на что-то ставить, а в центре обработки данных используются RACK -шкафы с рельсовыми системами. Другой проблемой является их охлаждение, поскольку со стандартной системой охлаждения внутри корпуса они начинают перегреваться и тротлиться (при достижении определенной максимальной температуры одного из ядер, понижается его частота, то есть устройства замедляют себя, чтобы остыть). В условиях тротлинга скорость инференса существенно падает.
Даже при этих проблемах осуществляются попытки создания промышленных решений по подобной схеме. Один из примеров можно увидеть по ссылке- http://nucserver.com .
Но мы сформировали для себя другую задачу: установка множества SBC с максимальной плотностью в серверный корпус форм-фактора U для получения серверного промышленного решения корпоративного сегмента для ЦОД с максимальной скоростью инференса.
Для решения этой задачи был использована U -корпус, куда были установлены одноплатные компьютеры NUC, без корпусов. Система охлаждения была доработана таким образом, чтобы при максимальной нагрузке ни один из NUC'ов не уходил в тротлинг. Поскольку в одном корпусе находится множество устройств, подключать к каждому сетевой провод не удобно и такого их количества нет в серверной стойке. Внутрь корпуса U был установлен сетевой маршрутизатор. На него приходит один сетевой провод в стойке, а далее трафик распределяется между NUC (вычислительными узлами). Для централизованного управления используется Terminator. Это позволяет извне управлять множеством устройств одновременно, что упрощает их настройку, управление узлами, обслуживание и сопровождением.
В результате было получено высокопроизводительное стандартизированное устройство для корпоративного сегмента, позволяющее использовать существующую инфраструктуру центров обработки данных. Один такой сервер на базе NUC может обработать 80 HD потоков 15FPS, по 10 потоков на NUC. Аналогичный сервер на видеокартах Tesla T4 может обработать столько же, но стоит при этом в три раза дороже и имеет форм-фактор в 2-4U, т.е. занимает в два раза больше места в стойке.

ComBox NUC Server – крайне перспективное решение, которое с успехом может покрывать потребности корпоративного сегмента в производительных решениях, особенно учитывая его экономическую эффективность, как на этапе внедрения, так и эксплуатации. Нужно понимать, что это решение дешевое, эффективное, высокопроизводительное, но оно ориентировано на сегмент С orporate , его не получится применять в сегменте enterprise. Для Enterprise-решений мы предлагаем разработку на базе Intel VCA2 и платформах Asus/Gigabyte/Supermicro с 4 картами в форм-факторе 1U. Здесь удалось получить 15 потоков на 1 узел VCA2, что в сумме дает до 180 потоков Full HD на сервер. Фактически, это 12 Intel Xeon E3, 4 GPU Iris Pro 580 для энкодинга/декодинга и совместного инференса.
Подробнее о ComBox NUC сервер - https://nucserver.ru