Единственная сила, способная умерять индивидуальный эгоизм, — это сила группы (Эмиль Дюркгейм). Создание выборок для временных рядов имеет свои особенности, связанные с тем, что в реальности предсказания по времени происходят позже обучения. Этот принцип надо соблюдать и при валидации моделей. Создадим демонстрационный набор данных:

Простым способом создания выборок является отсечение по времени либо использование train_test_split. При этом следует помнить, что перед этим ряд следует упорядочить по времени и параметр shuffle установить в False:
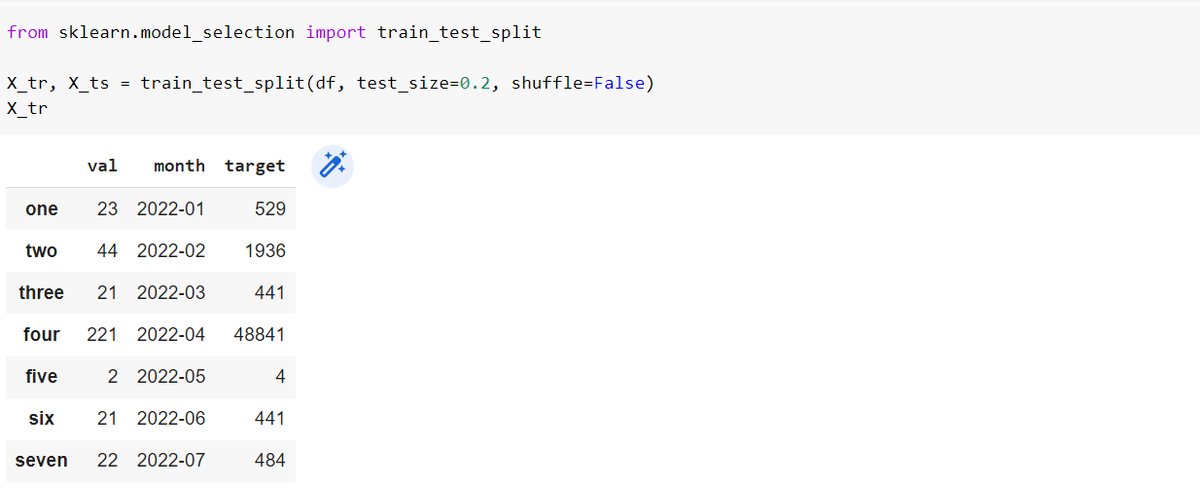
Еще в scikit-learn есть класс TimeSeriesSplit для проведения кросс-валидации. Он проходит n_splits раз по данным с расширяющимся окном так, чтобы в тестовую выборку попадали более поздние точки. Каждая новая тренировочная выборка является расширением старой с добавлением новых точек, а размер тестовой не меняется просто захватываются более "свежие" точки. По умолчанию размер тренировочной выборки на cплите i (всего n_splits): i * n_samples // (n_splits + 1) + n_samples % (n_splits + 1), а тестовой: n_samples//(n_splits + 1):
Также можно увеличить разрыв между тренировочной и тестовой выборкой, используя параметр gap (убирает из тренировочной выборки gap последних наблюдений):