Привет, дорогой читатель!

Зарегистрируйтесь и получите доступ к бесплатному контенту. А также будьте в курсе нового учебного контента. Ссылка на учебную платформу:
Если материал полезен, то есть способ отблагодарить меня. Любая сумма будет отличной наградой и стимулом писать полезный контент для Вас.
Policy based routing) и множественные таблицы маршрутизации (аналог VRF-light в классических сетях) в Linux. Материал ниже - попытка разобраться в том, как жить если в плане сети необходимо больше, чем настройка банальных сетевых параметров IP/Маска, маршрута по умолчанию, статического маршрута. Все перечисленное – классический unicast роутинг (выбор next-hop-а исходя из адреса назначения). Но что делать, если у нас схема и сценарий сложнее? Что если Вам, как инженеру, необходимо реализовать гибкие сетевые политики не только на уровне сетевого оборудования, но и со стороны сервера на базе Linux? Будь то proxy с поддержкой мультитенантности или сервис доступный по нескольким аплинкам от независимых друг от друга провайдеров. Давайте вспомним (разберемся), а что это такое мультитенантность и зачем это может быть нужно:
Если абстрагироваться от контекста, то в общем случае мультитенантность — это возможность изолированно обслуживать пользователей (систем) из разных организаций (сегментов сети) в рамках одного сервиса (одной инсталляции или развертывания).
Т.е. если мы говорим о сосуществовании нескольких потребителей сетевых ресурсов в рамках одного сервиса (для простоты будем называть сервисом некоторую proxy на базе Linux), то потребуется возможность обрабатывать трафик по-разному (индивидуально). И тут на помощь приходят различные реализации технологий а-ля PBR и VRF-light. К счастью, в Linux это все есть! К моему горькому сожалению, в сети реально очень мало информации о том, как это все практически реализуется в популярных дистрибутивах на базе Linux. Информация абсолютно не структурирована и носит ознакомительный характер, нет привязки к практической задаче. Немного теории, а в конце - я тут в лабе все, что хотел попробовал, ну типа вроде работает. По мне так это не подход... В книгах по Linux в данные вопросы тоже не погружаются (ибо сетевая специфика), а 99,9% ориентирована на основную Linux "попсятину". Увы – на просторах Интернета лишь пазлы, а картинку собирай сам… Ну что же картинку я попытался собрать и делючь ей с Вами.
Главный посыл статьи - дать углубленное представление о Linux в контексте обработки (маршрутизации) трафика и снять "лишнее напряжение" :) при работе с этой прекрасной и поистине могучей Осью...
Важно помнить - правда в том, что любое ПО будь то IOS, NXOS, EOS, Junos, FortiOS и прочие есть ничто иное как надстройка (оболочка) над Linux. Поэтому, все, что могут эти операционки, может и Linux в руках замотивированного инженера. Предлагаю совместно, шаг за шагом разобраться с тем, как выглядит PBR и VRF-lite в Linux и реализовать реальную практическую задачу. В качестве рабочей операционки будем использовать дистрибутив Ubuntu 22.04 LTS. Разберемся, что такое netplan, опишем целевую конфигурацию сети в формате языка yaml. Потрогаем утилиты ifconfig, tcpdump, wireshark, netcat, netstat. Если актуально и интересно прошу под кат!
Решать будем следующую практическую задачу:
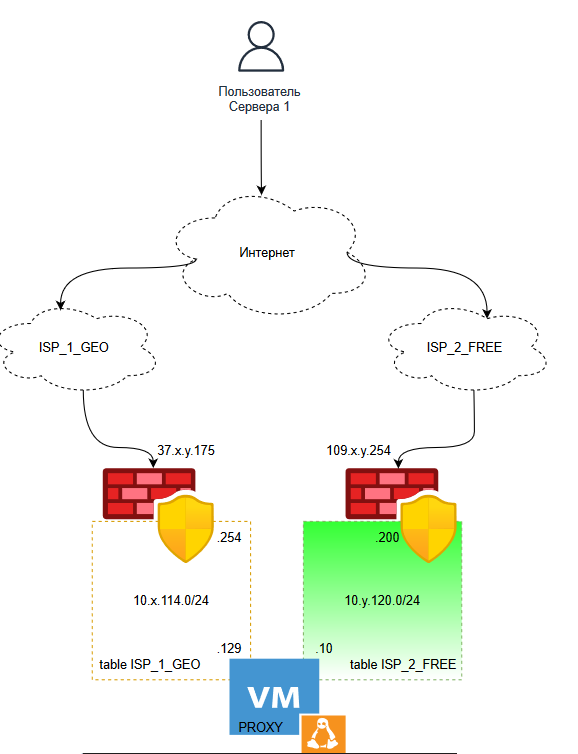
Необходимо разместить на машине с Ubuntu 22.04 LTS некоторый критичный сервис (в режиме revers-proxy), прослушивающий порт 8080 и обеспечить доступ к нему из сети Интернет по двум аплинкам независимых друг от друга провайдеров.
Особенности подключения к сети интернет (необходимо учитывать):
Имеем два независимых выхода в сеть интернет: 1-й с геофильтрацией (доступны только IP из Российского сегмента), 2-й без ограничений.
Схема (топология):
Решаем задачу:
Для начала настроим стык 10.x.114.0/24
Для конфигурирования сетевых параметров будем использовать
netplan (СММ - стильно, модно, молодёжно). Определение из man: netplan – YAML network configuration abstraction for various backends. Если простым языком, то netplan – это удобный менеджер управления сетевой конфигурацией. Он очень удобен с точки зрения описания целевой конфигурации и включает в свой инструментарий фичу автоматического отката конфигурации (netplan-try). netplan-try – пробует применить заданную конфигурацию и запускает таймер обратного отсчета. Когда отсчет завершен конфигурация откатывается в предыдущее состояние. Если вы сетевой инженер, то наверняка оцените данную фишку по достоинству, ибо она способна застраховать Вас от потери удаленного управления сервером.
Итак, заглянем в файл настройки конфигуратора:
nano /etc/netplan/01-network-manager-all.yaml
Я не буду в деталях погружаться в то, что такое NetworkManager (NM), но скажу, что нам необходимо сменить значение параметра renderer (программа для обработки конфигурации) c NetworkManager на networkd. Не забываем редактировать файл «01-network-manager-all.yaml» через sudo так как владелец файла – root. После внесения изменений в файл не забываем выполнить команду: sudo netplan apply для того, чтобы применить конфигурацию.
Теперь настроим IP адрес/маску и заодно DNS для стыка ISP_1_GEO:
С первого раза команда «netplan apply» не сработает так как systemd придется создать файл конфигурации и автоматически перезапустить саму себя. Поэтому придется ввести команду повторно и на этот раз все пройдет успешно:
Проверяем доступность шлюза 10.x.114.254:
На скрине видно, что сетевые настройки подхватились полноценно только после перезагрузки system-networkd. Дело в том, что изменение того, что уже есть в таблице маршрутизации это не сложная задача и netplan самостоятельно с ней справляется. Если же добавляется новый интерфейс или меняются политики маршрутизации, то зачастую придется перезапускать службу networkd вручную.
Связность имеем!
Теперь для доступа в интернет необходим маршрут по умолчанию. Настроим его. Но делать это мы будем уже не в глобальной таблице маршрутизации (Global RIB), а в предварительно созданной в файле /etc/iproute2/rt_tables. Данный файл относится к пакету ip-route (routing table management). Инструмент позволяет управлять таблицами маршрутизации. В изначальном состоянии файл rt_tables выглядит так:
По умолчанию определены три таблицы:
255 local – таблица к которую по умолчанию помещаются локальные адреса настроенных интерфейсов и соответствующие им broadcast адреса.
Посмотреть, что в этой таблице в данный момент просто командой
«ip route list table (local|255)»:
254 main – основная таблица, куда по умолчанию помещаются различные маршруты: маршруты по умолчанию (default gateways), подключенные маршруты (connected), статические маршруты (static routes). Для сетевого инженера будет удобно думать о таблице main как о Global RIB. Посмотреть, что в этой таблице в данный момент просто командой
«ip route list table (main|255)»:
Так как main это основная таблица маршрутизации (она же GRIB), то используя стандартную команду «ip route» или ее сокращённою версию «ip r» для вывода маршрутной информации получим такой же результат:
253 default – таблица для маршрутов по умолчанию (по логике названия). Но в данный момент она не используется на практике.
В выводах команд вы могли заметить аббревиатуру scope (с англ. масштаб, сфера, рамки). Мне лично сподручнее думать о scope, как о принадлежности (области видимости). На текущий момент в выводах наших команд можно встретить scope link и cope host. Есть еще scope global.
scope link: принадлежность – множество узлов подсети, область видимости – канал, широковещательный домен (адрес подсети);
scope host: принадлежность – конкретный хост/сервер (адрес хоста), область видимости – в пределах хоста/сервера;
scope global: принадлежность – хост/сервер (адрес хоста/маска), область видимости – виден всем узлам подсети.
Так же разберем аббревиатуру proto (так же известный как route protocol). Данный параметр определяет источник того или иного маршрута. Когда вы настраиваете IP адрес и маску, то ядро системы самостоятельно высчитывает адрес подсети и помещает его в таблицу main с параметром kernel. Т.е. kernel – то, что сформировала сама операционка. Static – то, что настроил ручками админ. Есть еще boot – означает временность параметра, действующего в рамках текущего uptime системы.
Итак, вернемся к маршруту по умолчанию. Создадим отдельную таблицу маршрутизации под названием ISP_1_GEO с номером 252. Можно добавить ручками в файл rt_tables, а можно дописать в файл таким образом:
sudo -i && echo "252 ISP_1_GEO" >> /etc/iproute2/rt_tables
теперь файл rt_tables выглядит следующим образом:
Применяем текущую конфигурацию, и смотрим содержание таблицы с номером 252:
Попробуем пингануть DNS сервер Яндекса:
Результат предсказуем - все потому, что этого недостаточно для того, чтобы схема заработала! Необходимо создать SBR (source base rule) правило, указывающего на необходимость заглянуть в таблицу 252 для поиска маршрута по умолчанию. Правила содержатся в таблице, содержание которой можно вывести командой «ip rule list»:
Зеленая стрелочка указывает на порядок просмотра правил в таблице. Каждое обращение операционной системы к данной таблице завершается по достижению первого подходящего правила либо конца таблицы. Слева вы видите значения приоритетов, справа сами правила обработки трафика. Выше я упоминал о том, что таблица local содержит адреса типов local и broadcast. С просмотра данной таблицы ядро операционки начинает процесс принятия решения о том какой интерфейс задействовать для обработки трафика и куда этот трафик направить далее. Именно поэтому правило для таблицы local имеет нулевой (т.е. самый высший) приоритет просмотра. Таблица main же в свою очередь – зеркальное отражение нашей Global RIB в которой следующее содержание:
Вы уже видели содержание данной таблицы. Ее по умолчанию можно вывести командой «ip route». А таблица default в настоящее время пустует и на практике никак не используется.
Чего нам не хватает?
Нам в данной таблице не хватает правила для новой таблицы 252 (ISP_1_GEO). Добавим его!
Можно из консоли, но этот способ обычно используют при проверках и траблшутинге. После перезагрузки системы правила добавленный из консоли пропадут. Поэтому добавим их на постоянку в конфигурационном файле netplan-а:
Сохраняем, выходим, делаем netplan apply и смотрим таблицу правил.
Итак, проверяем связность до DNS сервера Яндекса:
Связность есть!
И что мне особо нравится в данном подходе это то, что при выводе маршрута по умолчанию для указанного IP адреса система нам выводит информацию о том в какой таблице найден этот шлюз по умолчанию. Это очень удобно при условии, если вы задали понятное обозначение в файле rt_tables.
Шлюзом по умолчанию у нас является межсетевой экран, на котором я предварительно настроил static NAT: 37.x.y.175 -> 10.x.114.129. Как вы помните задача в том, чтобы сервис, прослушивающий порт 8080 был доступен одновременно через обоих операторов. Проверим доступность через ISP_1_GEO! Полноценный сервис нам не понадобится. Для проверки нам будет достаточно утилиты netcat (англ. net сеть + cat) — утилита Unix, позволяющая устанавливать соединения TCP и UDP, принимать оттуда данные и передавать их. Делается все просто:
Далее утилитой netstat мы проверяем, что действительно создали слушающий сокет. Параметры: t- TCP, l – состояние listen (прослушка), p – дополнительно выводится информация о процессе, слушающем данный порт (PID/Program name), n -numeric (указываем выводить информацию в числовом формате).
Итак, теперь для проверки нам потребуется обратиться из сети интернет telnet-ом на белый адрес:
Если результат – соединение провалилось в черный экран:
То telnet соединение установлено успешно. Однако давайте удостоверимся в этом на стороне самого сервера той же утилитой netstat:
Проделаем все тоже самое, но уже для стыка со вторым оператором!
В такой конфигурации, если не определять исходящий интерфейс, будет выбираться интерфейс ens160 и шлюз ISP_1_GEO, так как правило 32768 приоритетнее. Однако если однозначно определить интерфейс, то будет работать конкретное правило:
Уже в данной конфигурации работает отказоустойчивость для исходящего трафика. Дело в том, что если отключить интерфейс ens160, то iproute автоматически уберет правило из таблицы и трафик пойдет через ISP_2:
На L3 уровне мы даже не увидим потерь:
L3 – хорошо, а что с L4?
По идее сессия должна разорваться! Давайте соберем трафик с помощью tcpdump и посмотрим, что произойдет в момент отключения основного интерфейса.
Для сбора трафика запустим tcpdump следующим образом:
Для начала, перед тем как выключить интерфейс ens160 посмотрим какой у нас внешний IP:
Переходим на главную страницу сайта habr.com и отключаем интерфейс ens160 командой «sudo ifconfig ens160 down» Опять смотрим какой у нас внешний IP:
Все логично! Теперь трафик пошел через ISP_2_FREE. При этом на уровне TCP сессии в дампе мы видим, что сессия была корректно завершена:
В данном примере мы корректно выключили интерфейс ens160 поэтому TCP/IP стек операционки корректно завершил сессию. Если выключить интерфейс жестко, то сессия со стороны habr.com повиснет на время timeout в состоянии FIN WAIT -> TIME WAIT.
Итак, для исходящего трафика все ОК!
Теперь проверим выполнили ли мы задачу полностью, т.е. доступен ли кричный сервис, прослушивающий порт 8080 через оба оператора одновременно. И не влияет ли отказ одно из операторов на доступность через альтернативу. Запускаем netcat как делали это ранее. И выполняем telnet на порт 8080 по публичному IP ISP1 и ISP2:
Давайте глянем netstat-ом, что происходит:
Подключаясь через ISP_2_FREE все ОК, а вот подключаясь через ISP_1_GEO tcp сессия застревает в состоянии SYN_RECV. Дело в том, что при текущем содержании ip rule list:
возникает асимметрия входящего и исходящего трафика.
Шлюз в сторону ISP_2_FREE ничего не знает, о NAT-е через шлюз в сторону ISP_1_GEO.
На момент проверки телнетом активным правилом было правило маршрутизации через ISP_2_FREE (так случилось при проведении эксперимента с отключение и обратным включением интерфейса ens160). Данное явление называется кешированием правил маршрутизации. Выполним команду сброса кеша вручную и перезапустим netplan:
sudo ip rule flush && ip route flush cache&& sudo netplan apply
После этих манипуляций текущее содержание правил будет загружено в ядро и трафик будет обрабатываться предсказуемо.
Внимание! В реальной жизни советую при первом прогоне команд с использованием netplan использовать не apply , а try. Так в случае, если у вас отвалится доступ до машины, конфигурация вернется в исходное состояние и доступ возобновится. По умолчанию таймер обратного отчета стартует со значения 120 секунд (можно уменьшить). Если после применения команды netplan try вы видите, как идет обратный отсчет, то доступ у вас не отвалился и следующим шагом применяйте netplan apply.
*All RPDB rules are loaded into the kernel’s memory when the server starts up. If you make changes to ip rules or ip routes and wish to utilize them prior to the next system reboot, you must flush their cache. This forces the kernel to reload the respective databases.
Перевод: Все правила политик маршрутизации загружаются в память ядра при старте системы. Если вы вносите изменения в ip rules или ip routes и хотите, чтобы они применились до следующего рестарта системы, то необходимо отчистить кэш. Это вынудит ядро загрузить соответствующие базы.
Чтобы привести входящий и исходящий трафик по обоим операторам к симметрии при любых сценариях, то понадобится еще два дополнительных правила:
Зачем понадобились правила SBR с указанием конкретных IP интерфейсов. Дело в том, что правила 32768 и 32769 применяются для любых SRC адресов. Если к примеру входящая TCP сессия пришла на адрес 10.159.120.10, то SYN+ACK пакет будет иметь SRC адрес 10.159.120.10 и такой пакет попадет под правило 32768 из-чего исходящий пакет пойдет ассиметрично. Правила 100 и 200 выравнивают ситуацию и делают входящий и исходящий трафик симметричными:
Задача выполнена! Если статья понравилась поддержите лайком и велком в комментарии!) Рад буду вопросам, дополнениям, корректировкам.
Так же напоминаю, что существует телеграмм канал https://t.me/info_comm. Там много материала, который не публиковался на Дзене. Если вам актуален материал, то там вы можете найти еще много полезного для себя!
До встречи!