Чтобы помочь инженерам в крупных и малых компаниях проанализировать большие и малые данные, инженеры-электронщики из Национального института стандартов и технологий (НИСТ) США выпустили широкие спецификации по созданию полезных инструментов для решения этой задачи. Документ - окончательная версия «Системы функциональной совместимости больших данных НИСТ», он стал результатом многолетней совместной работы института и более чем 800 экспертов из промышленности, научных кругов и государственных органов.
Он заполняет девять томов и предназначен для того, чтобы помочь разработчикам в развертывании программных средств, которые могут анализировать данные с помощью любого типа вычислительной платформы - от одного ноутбука до самой мощной облачной среды. Не менее важным является то, что он позволяет аналитикам перемещаться с одной платформы на другую и заменять более совершенные алгоритмы без переоборудования вычислительной среды.

Говорит Во Чанг, специалист по информатике НИСТ:
« Мы хотим, чтобы ученые, занимающиеся обработкой данных, выполняли эффективную работу на любой платформе, которую они выбирают или имеют в наличии, и чтобы их работа развивалась или изменялась. Эта структура является справочным пособием по созданию «агностической» среды для создания инструментов. Если поставщики программного обеспечения при разработке аналитических инструментов используют рекомендации фреймворка, то результаты аналитиков могут поступать непрерывно, даже при изменении их целей и развитии технологий».
Подобная концепция удовлетворяет давние потребности инженеров-данных и ученых, которым предлагается извлекать полезную информацию из все более крупных и разнообразных наборов данных при навигации по меняющимся технологиям.
Операционная совместимость становится все более важной по мере поступления огромного объема данных с растущего числа платформ, начиная от телескопов и физических экспериментов и заканчивая бесчисленными крошечными датчиками и устройствами, связанными с IoT и IIoT. Хотя несколько лет назад мир генерировал 2,5 эксабайта (миллиард байт) данных в день, по прогнозам, к 2025 году это число достигнет 463 эксабайт. (Это количество данных заполнит 212 миллионов DVD).
Компьютерные специалисты используют термин «анализ больших данных» для обозначения системных подходов, которые пытаются извлечь полезную информацию из этих больших массивов данных. С быстрым ростом числа и разнообразия инструментов, созданных для решения этой задачи, ученые, занимающиеся обработкой данных, теперь могут расширить масштабы своей работы от единичных, небольших настольных вычислений до крупной распределенной облачной среды с большим количеством процессорных узлов.
Но зачастую такой сдвиг предъявляет огромные требования к аналитикам. Например, инструменты, возможно, придется перестраивать с нуля, используя другой компьютерный язык или алгоритм, оценивая затраты времени персонала и потенциально критичные с точки зрения времени соображения.
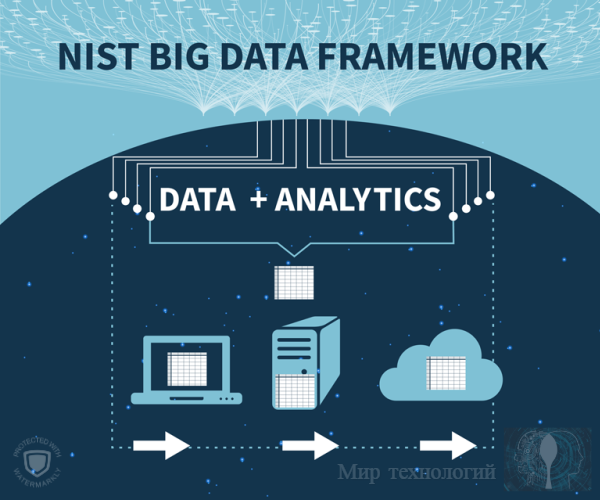
Предполагается, что система NIST Big Data Interoperability Framework (NBDIF) поможет создать программные средства, которые могут анализировать данные с помощью любого типа вычислительной платформы и легко перемещаться с одной платформы на другую.
Система НИСТ представляет собой попытку решить эти проблемы. Он включает консенсусные определения и таксономию, чтобы помочь гарантировать, что разработчики будут на одной странице, когда они обсуждают планы по новым инструментам. Она также включает в себя ключевые требования к безопасности данных и защите конфиденциальности, которые должны быть у этих инструментов. Также появилась новая спецификация справочной архитектуры интерфейса для руководства по использованию этих инструментов.
«Архитектурный интерфейс позволит производителям создавать гибкие среды, в которых любой инструмент может работать», - говорит Чанг. «Раньше не существовало спецификаций по созданию интероперабельных решений».
Такая оперативная совместимость помогла бы аналитикам решать ряд проблем, требующих большого объема данных, таких как прогнозирование погоды. Метеорологи разделяют атмосферу на небольшие блоки и применяют аналитические модели для каждого блока, используя методы Больших данных для отслеживания изменений, намекающих на будущее.
По мере того, как эти блоки становятся меньше, а способность анализировать мелкие детали возрастает, прогнозы могут улучшаться, если вычислительные компоненты могут быть заменены на более совершенные инструменты.
«Вы моделируете эти блоки с несколькими уравнениями, переменные которых движутся параллельно. Трудно отследить их всех. Агностическая среда структуры означает, что метеоролог может поменять существующую модель на более совершенную. Это даст синоптикам большую гибкость».
Другим возможным применением является открытие лекарственных препаратов, где ученые должны исследовать поведение нескольких белков-кандидатов на активные вещества в ходе цикла тестов, а затем передать результаты в следующий отдел. В отличие от прогнозирования погоды, когда аналитический инструмент должен отслеживать изменения сразу нескольких переменных параметров, разработка лекарственных препаратов порождает длинные цепочки данных, в которых изменения происходят последовательно.
Хотя эта проблема требует иного подхода к Большим данным, она все равно выиграет от возможности легко измениться, поскольку разработка лекарственных средств уже является трудоемким и дорогостоящим процессом.
Применимо ли это к тем или иным проблемам, связанным с большими данными - от выявления случаев мошенничества в сфере здравоохранения до идентификации животных по образцу ДНК - ценность системы заключается в том, что она поможет аналитикам говорить друг с другом и легче применять все необходимые инструменты данных для достижения своих целей.
«Аналитика с использованием новейших методов машинного обучения и искусственного интеллекта при использовании старых статистических методов будет возможна», - говорит Чанг. «Любой из этих подходов сработает, и эталонная архитектура позволит вам сделать выбор».




















